错误日志(Error Log) 用于记录在服务 启动、运行及停止 过程中遇到的各种错误信息。该日志功能默认启用,且默认保存在 Linux 系统的 /var/log/mysqld.log(或 /var/log/mysql/error.log)路径下,也可能在 data 目录中以主机名为 .err 后缀的文件方式存在。若想查看或修改该路径,可通过 MySQL 命令:
1 | SHOW VARIABLES LIKE '%log_error%'; |
该命令会显示当前 log_error 变量的值,即错误日志所在路径。如果该变量为空,通常默认日志会被输出到 stderr,或由系统服务(如 systemd)转至系统日志(如 /var/log/messages 或由 journalctl 管理)。
二进制日志(Binary Log) 会记录所有成功执行的 DDL(结构定义语句)和 DML(数据操作语句),但不会包含纯查询类语句(如 SELECT、SHOW)。它以 Event 形式记录,并且保存每条语句执行的时间戳。默认情况下启用二进制日志,并常用于数据备份以及主从复制场景。
二进制日志系统包括两类文件:
- 索引文件(.index):跟踪所有二进制日志文件的路径;
- 日志文件(形如 .00000*):具体记录 DDL 与 DML 的事件。
日志的记录格式有三种:
- STATEMENT:以文本形式记录每条 SQL,并不包含事务上下文、权限或系统状态;
- ROW:以二进制形式记录行数据的变化(旧值和新值);
- MIXED(MySQL 8.0 以上默认):通常使用 STATEMENT,在涉及非确定性函数(如
NOW()、UUID()等)时自动切换到 ROW 格式。
针对日志清理,常用命令如下:
RESET BINARY LOGS;(或旧版本的RESET MASTER;)将删除所有二进制日志,并将索引重置,只保留一个新的空日志文件(编号从 .000001 开始);PURGE BINARY LOGS TO 'binlog.xxx';删除指定日志文件之前的所有日志;PURGE BINARY LOGS BEFORE 'YYYY‑MM‑DD hh:mm:ss';删除该时间之前生成的所有日志。
此外,可以设置系统变量(如 binlog_expire_logs_seconds 或旧版的 expire_logs_days)实现自动清理过期日志,默认保留期为 30 天。
更多关于 binlog 的信息,可参考:https://www.cnblogs.com/rickiyang/p/13841811.html
二进制日志(binlog) 功能可以通过在 my.cnf 或启动参数中设置来进行全面配置,下面是一些常用选项与管理方法:
启用与路径配置:log‑bin=/home/mysql/binlog/
该参数不仅开启 binlog 功能,还指定日志文件的存放目录。如果不指定路径,MySQL 默认将日志保存在数据目录,并以主机名或 binlog 为基础名生成一系列 .00000* 日志文件。
文件大小与保留周期:
max_binlog_size=104857600将单个日志文件最大限制为 100 MB。expire_logs_days=7设置日志自动保留时限为 7 天,超过该时长的日志文件会被系统定期清理。
过滤数据库:
可以通过以下参数控制哪些库的更新被记录到 binlog:
binlog-do-db=db_name:仅记录指定数据库的变更。binlog-ignore-db=db_name:忽略指定数据库的更新,不写入日志。
同步策略:
sync_binlog=0 表示不强制让 MySQL 将日志立即同步到磁盘,交由操作系统定期执行。该配置提高性能,但在主机崩溃时可能丢失最后一部分日志;若设为 1,则在每次提交时都 fsync,一致性高但性能略受影响。
查看当前设置:
可以执行以下命令确认配置状态:
SHOW BINARY LOGS;:列出当前所有 binlog 文件;SHOW MASTER STATUS;:查看主服务器正在使用的最新日志名称与位置;SHOW VARIABLES LIKE '%log_bin%';:确认二进制日志是否已启用及其路径;SHOW VARIABLES LIKE '%binlog_format%';:查看当前记录格式(STATEMENT、ROW 或 MIXED);SHOW VARIABLES LIKE '%binlog_expire_logs_seconds%';:检查自动过期设置(通常是以秒为单位)。
手动恢复流程:
- 停止 MySQL 服务;
- 利用 mysqlbinlog 工具分析
.00000*中的日志,确认误操作发生前的起始与结束位置; - 清空当前数据库以准备恢复;
- 执行命令:
mysqlbinlog --start-position=xxx --stop-position=yyy bin-log.00000x > recover.sql,其中 start-position 为误操作前最近一次安全点,stop-position 为误前最后一条正常语句的位置; - 将导出的 recover.sql 文件导入数据库,恢复指定段的变更。
一般查询日志记录了MySQL 服务器的所有连接信息和客户端的所有操作语句,默认是不开启的。
慢查询日志用于记录执行时间超过 long_query_time(默认 10 秒)并且扫描记录数不少于 min_examined_row_limit 的 SQL 语句,以帮助识别并优化效率低下的查询。注意,这一功能默认处于关闭状态,开启后不包含管理语句(如 ALTER、CREATE INDEX)及未使用索引的查询,除非你通过以下两个系统变量特别配置:
log_slow_admin_statements:启用后,允许记录管理类语句;log_queries_not_using_indexes:启用后,记录所有不使用索引的查询(并不限于慢查询)。
日志触发条件的判断顺序如下(MySQL 8.0+):
- 是不是管理语句,或已启用
log_slow_admin_statements; - 查询执行时间 ≥ long_query_time,或启用
log_queries_not_using_indexes并且未使用索引; - 扫描的行数 ≥ min_examined_row_limit;
- 若启用了该选项,还会受
log_throttle_queries_not_using_indexes(对未用索引查询加速限流)的影响。
简而言之,慢查询日志只有在 SQL 足够慢或扫描量大时才会记录,且默认不记录管理或索引缺失的语句,除非明确启用相关变量。若需全面监控优化目标,建议根据实际情况调整这三项核心参数。
重做日志(redo log) 专门记录已提交事务所做的页面级别修改,以确保在崩溃或异常关机后能够快速恢复数据一致性。与完整行记录不同,redo log 只保存页号(Page ID)和偏移量(Offset)处的数据从旧值到新值的变化,例如在页面 12345 的偏移量 256 位置,将值从 25 修改为 30,既紧凑又高效。这些日志文件通常组成一个循环队列:当当前日志文件写满后,InnoDB 会切换到下一个文件,直到用尽后再回到第一个文件,覆盖最早的日志。
其工作流程如下:
- 事务开始与修改缓冲:当事务对表中数据进行修改时,InnoDB 先将修改记录写入内存中的 redo log buffer;
- 事务提交与刷盘:提交时,buffer 中的内容根据
innodb_flush_log_at_trx_commit参数设置,或直接刷入磁盘(值为 1)、或先写入操作系统缓冲区后由系统决定何时落盘(值为 2)、或不强制落盘以提升性能但有丢失风险(值为 0); - Checkpoint 协同:后台 Checkpoint 进程周期性地将内存中的脏数据页同步到表空间文件(
*.ibd),并将对应的 redo log 日志标记为可覆写,维持循环日志的持续运作。
通过这种设计,InnoDB 能够在最短时间内重做已提交的事务修改,快速恢复数据库到故障发生前的一致状态。
假设在表空间 1 中,对页 42 的偏移 128 处的某条记录的第 3 个字段(如 age)执行更新,将其从 25 改为 30,则对应的 redo 日志项可示意如下:
1 | [MLOG_REC_UPDATE_IN_PLACE] |
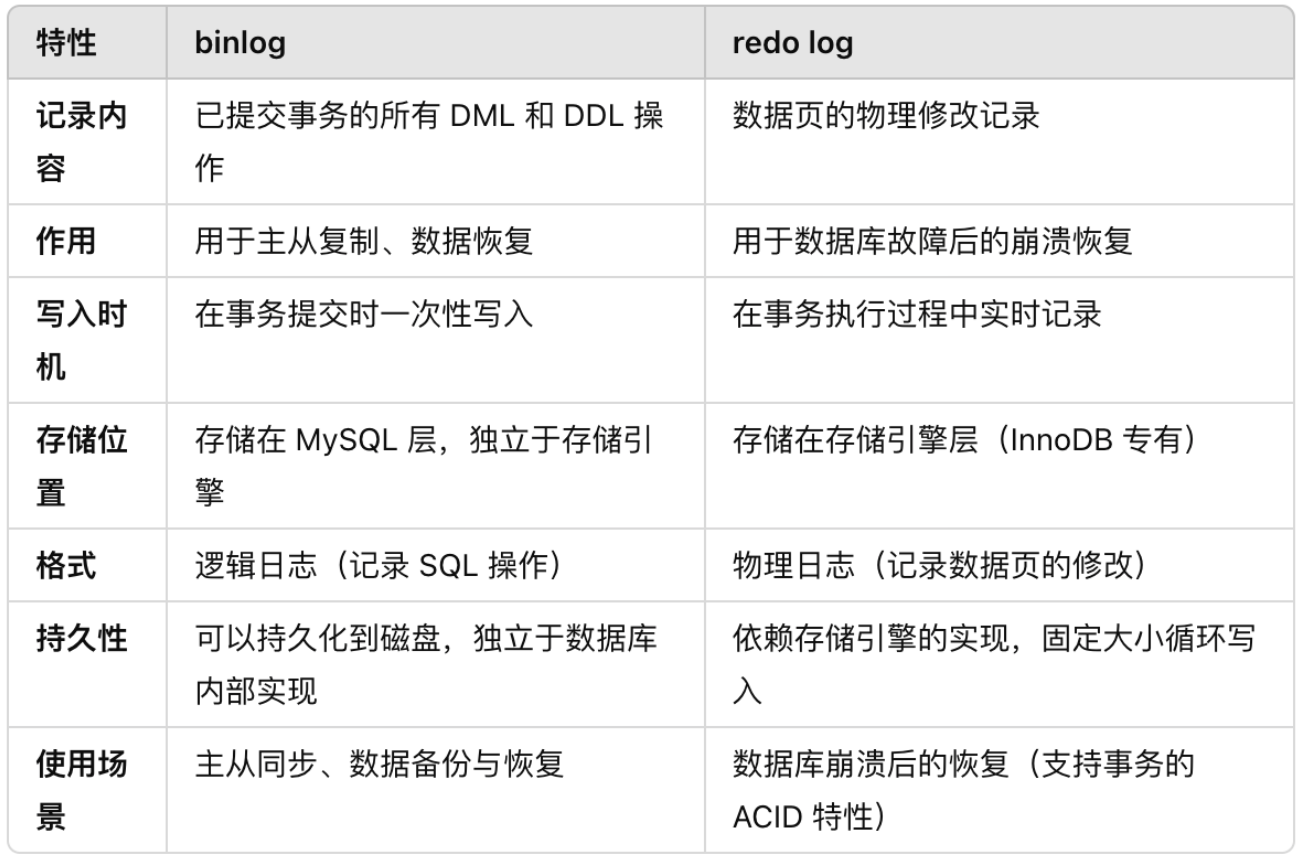
binlog 和 redo log 的区别如下表:
回滚日志(Undo Log) 用于在事务回滚和多版本并发控制(MVCC)中保存数据修改前的旧值。当事务开始时,InnoDB 会初始化事务上下文;在执行更新、删除等修改操作时,它首先将当前行的原始数据写入 undo log,同时将对应的物理改动记录到内存中的 redo log buffer;如果事务提交,则会将 redo 日志刷新到磁盘,并将该事务所产生的 undo 日志标记为无效,待后台清理;若事务选择回滚,则 InnoDB 会读取 undo log 中的旧值,将数据恢复到修改前的状态,并在回滚完成后清理相关的 redo 日志。这样既保证了未提交事务的可回滚性,也为 MVCC 提供了版本快照支持。