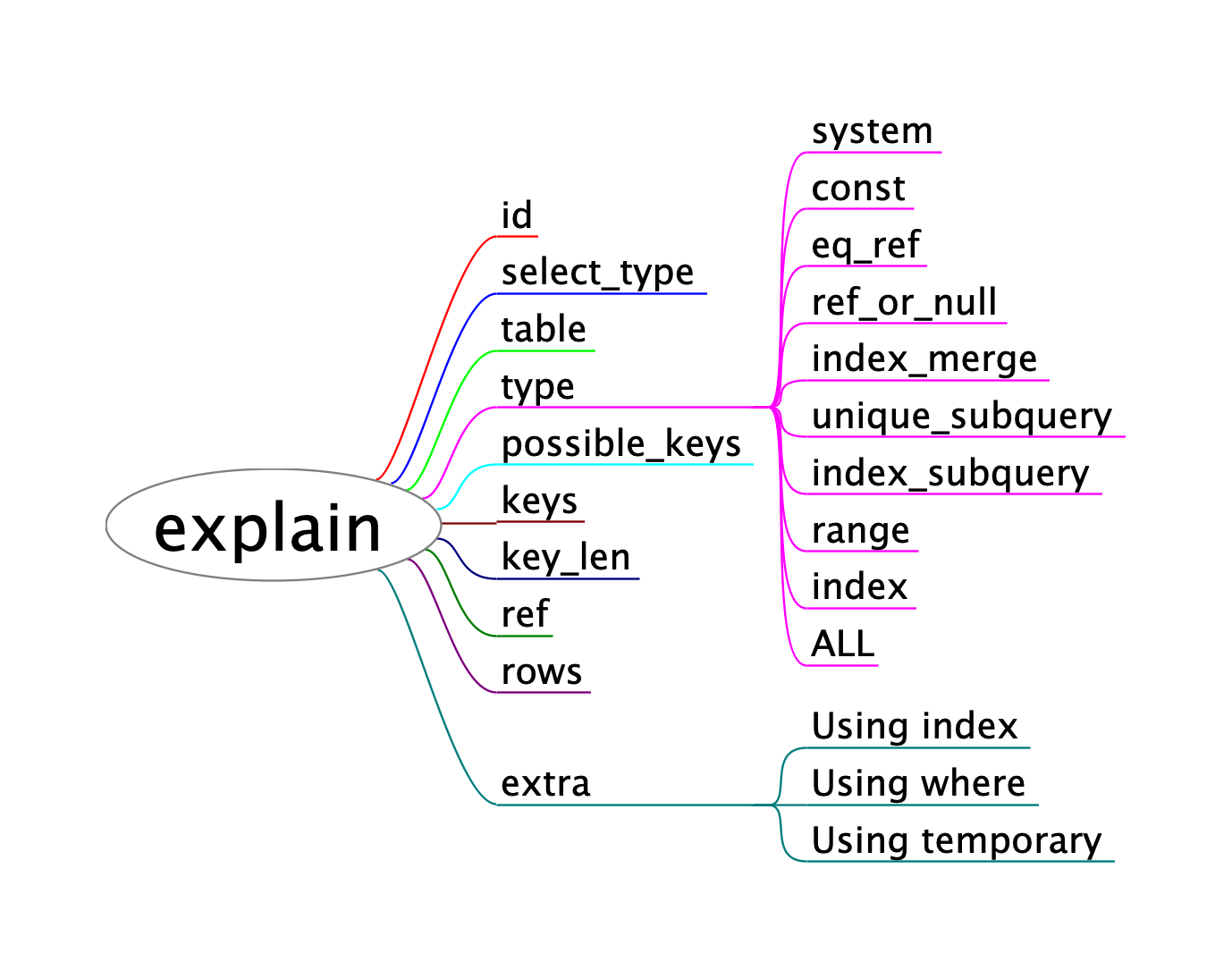
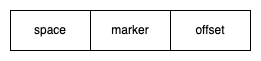
SELECT*FROM users WHERE age >30AND city ='Los Angeles';
在未启用索引下推时,InnoDB 存储引擎仅依据 age > 30 的索引范围扫描收集所有符合该条件的行,并将它们一股脑儿地返回给 MySQL 服务器层,由服务器再对 city = 'Los Angeles' 条件逐行筛选;而启用索引下推后,存储引擎会在索引扫描阶段同时评估 age > 30 与 city = 'Los Angeles' 两个条件,只有同时满足的行才会被送到服务器层,从而避免了无谓的行回表和服务器级过滤,显著减少了 I/O 操作并提升了查询性能。实际执行时,若在 EXPLAIN 的 Extra 列中看到 Using index condition 即表示已启用这一优化。
在 MySQL 中,任何无法直接利用索引有序性完成的 ORDER BY 操作都会触发 filesort:存储引擎先全表(或范围)扫描读取所有匹配行,将它们放入排序缓冲区(sort_buffer)中完成内存(或磁盘)排序后再返回结果;而如果能建立一个正好覆盖排序字段并且包含查询所需列的索引(Using index),MySQL 则可通过顺序扫描该索引直接输出有序结果,无需额外排序,效率更高。例如:
1 2 3
SELECT age, phone FROM table_name ORDERBY age ASC, phone DESC;
若事先创建:
1 2
CREATE INDEX idx_user_age_pho_ad ON table_name(age ASC, phone DESC);
在 MySQL 中,如果将用于 GROUP BY 的列定义在符合最左前缀规则的复合 B+Tree 索引上,服务器就可以直接沿着索引的有序叶节点执行分组操作,而无需使用临时表或 filesort,从而显著提高聚合查询性能;例如对于 GROUP BY(a, b) 的场景,只要存在 (a, b, …) 这样的复合索引,MySQL 就能利用该索引在扫描叶节点时即完成对 (a,b) 键值的分组,而不是先拉取所有行再在服务器层排序和分组。
在 MySQL 中,COUNT(column) 最慢,因为引擎要逐行取出指定列的值并判断是否为 NULL,只有非空值才累加;COUNT(primary_key) 略快一些,因为主键列本身有 NOT NULL 约束,无需判断空值即可累加;COUNT(1) 与 COUNT(*) 在现代 MySQL 中被优化为等价操作,它们都不实际读取任何列值,而是在服务层对每行隐式累加一个常量,性能十分接近,通常是最快的计数方式。
InnoDB 的行锁实际上是对索引记录(index record)加锁,而非对物理存储行本身加锁:当执行带有 WHERE 条件的 UPDATE、DELETE 或 SELECT … FOR UPDATE 时,InnoDB 会在匹配条件的索引叶节点上设置记录锁和必要的间隙锁,从而实现行级并发控制;但如果查询条件无法利用任何合适的索引,InnoDB 就必须扫描整个表并在聚簇索引(或隐式主键索引)上对所有记录加锁,这时就会退化为表级锁,阻塞全表写操作;同样地,若使用的索引失效(例如对非索引列做范围扫描或函数运算),也会触发锁粒度升级为表锁,导致并发性能急剧下降。因此,为了保持细粒度的行锁并避免意外的表锁锁阻塞,务必为常用的查询条件列创建合适且选择性高的索引。
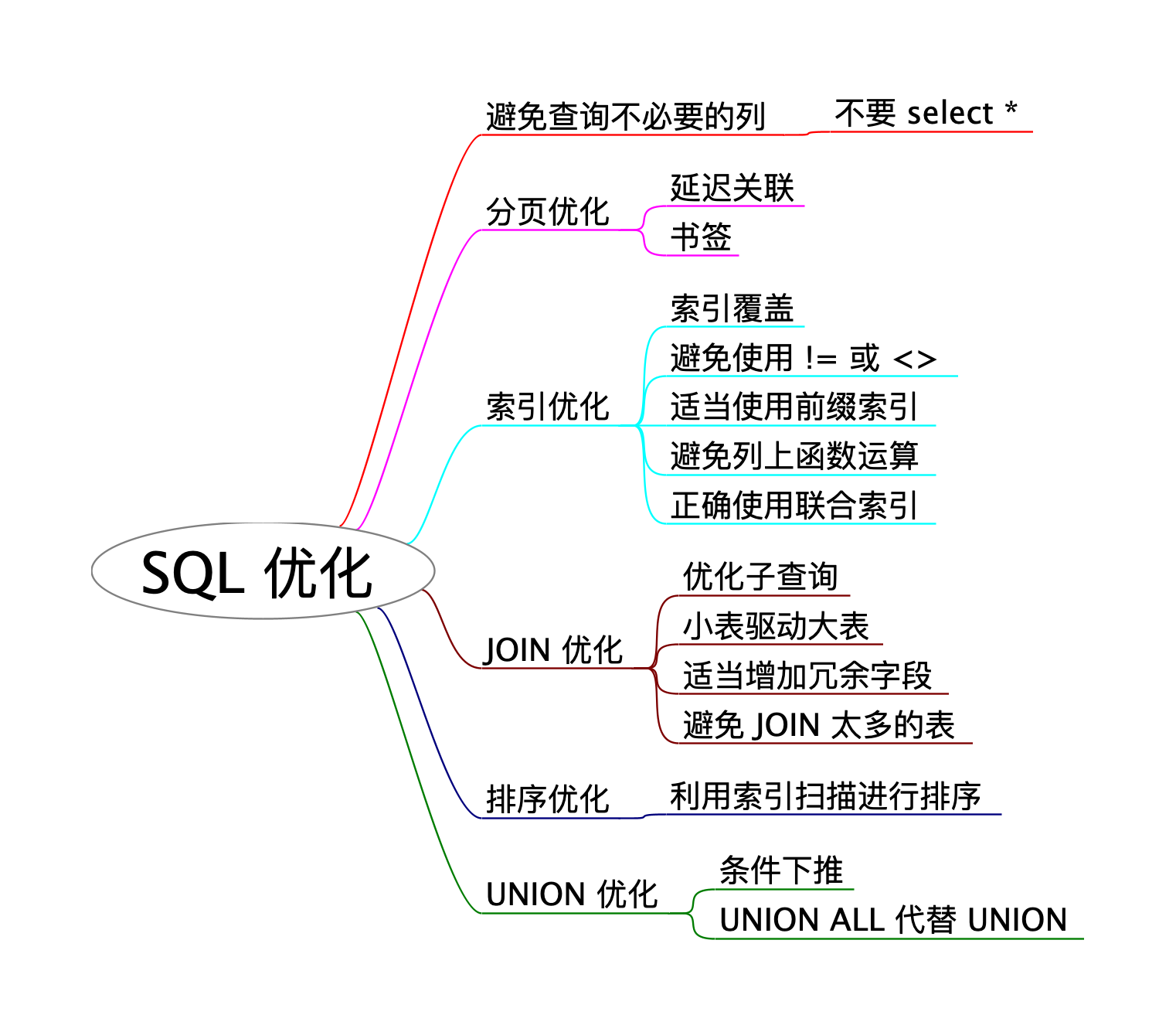
union 优化
在使用 UNION 语句时,为了让优化器更高效地执行查询,应将共同的过滤条件(如 WHERE)和分页限制(如 LIMIT)尽可能下推到各个子查询中,这样每个子查询只需处理满足自身子集条件的行,并在各自范围内完成截取与过滤,避免先将所有子查询结果合并后再做统一筛选,从而减少中间结果集的大小、降低 I/O 与内存开销,并加快整体查询响应速度。
MySQL 数据库 cpu 飙升的话,要怎么处理呢?
在 MySQL 出现 CPU 飙升时,首先可借助操作系统工具(如 top 或 htop)确认是 mysqld 进程占用过高,接着在数据库层面执行 SHOW PROCESSLIST 或查询 information_schema.processlist,快速定位执行时间或状态异常的会话,并对最耗资源的 SQL 做 EXPLAIN 分析,检查是否缺失索引或数据量过大;发现可疑线程后,可使用 KILL 语句终止它们,同时观察 CPU 是否回落,然后针对性地优化(如新增索引、重写慢查询、调整内存参数等)并重新执行这些 SQL;此外,如果是大量会话瞬间涌入导致 CPU 突增,则需与应用方协同排查连接激增的原因,并可考虑设置最大连接数或在业务层做限流,以防过多并发请求压垮数据库服务器。
SELECT u.*, o.* FROM ( SELECT user_id FROM users WHERE some_condition -- 这里是对小表进行过滤的条件 ) AS filtered_users JOIN orders o ON filtered_users.user_id = o.user_id WHERE o.some_order_condition; -- 如果需要,可以进一步过滤大表
然后,我们可以重构查询语句,比如说使用 LIMIT 分页来避免返回大量数据:SELECT * FROM table_name WHERE condition LIMIT 100;,或者可以明确查询字段:SELECT column1, column2 FROM table_name WHERE condition;,避免运行 SELECT *;,再者可以在 JOIN 字段上设置索引,并尽量减少复杂的嵌套查询。
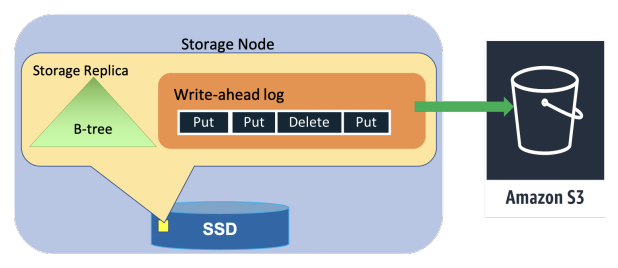
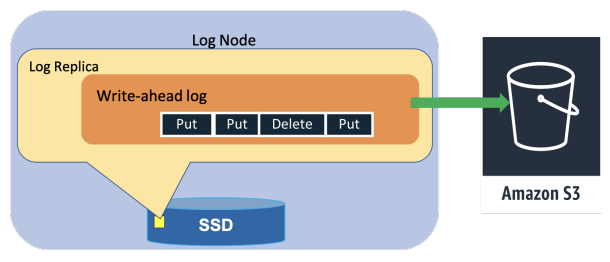
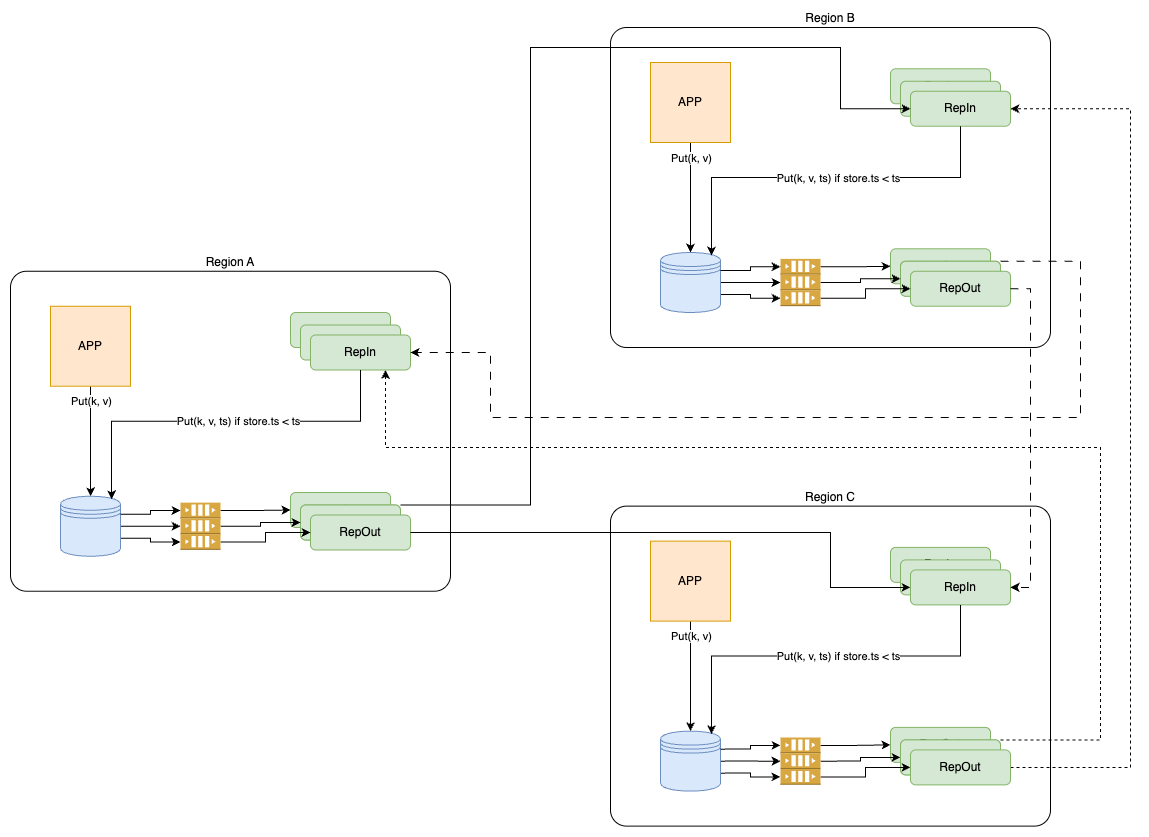
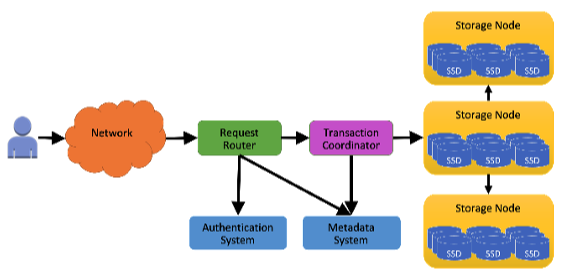
在大型服务中,内存或磁盘等硬件故障时有发生。一旦某个节点发生故障,该节点上承载的所有复制组就会降至两份副本。修复存储副本的过程可能需要数分钟,因为此过程不仅要复制 B 树结构,还要复制预写日志。为快速恢复,当领导副本检测到某个存储副本不健康时,它会立即添加一个日志副本,以确保持久性不受影响。添加日志副本只需几秒钟,因为系统只需从健康副本拷贝最近的预写日志,而无需复制 B 树结构。通过这种仅复制日志的快速修复方式,DynamoDB 能够在绝大多数情况下,保证最近写入操作的高持久性和系统的持续可用性。
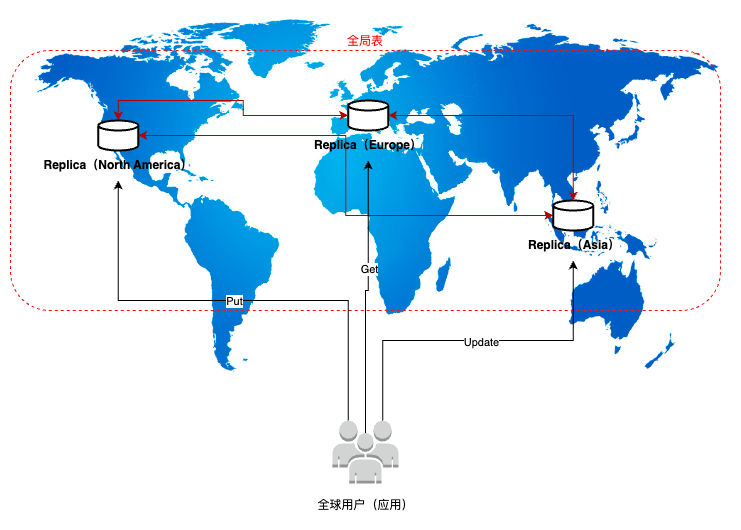
如果某个 Region 宕机,全局表继续在其他 Region 上读写,不受影响。宕机区域恢复后,会自动同步补全所有挂起写入数据,无需人工干预。
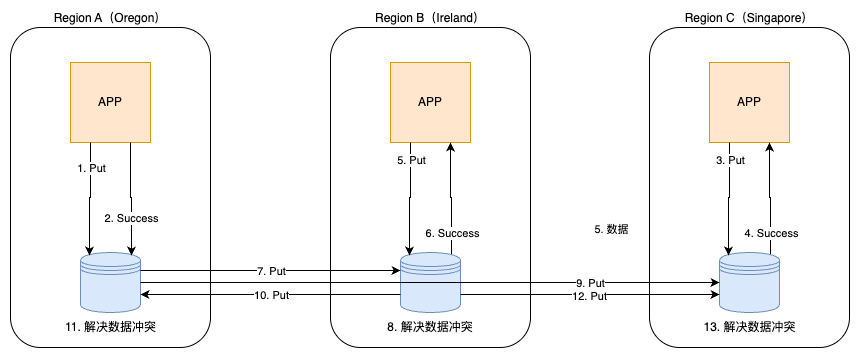
假设有两个区域 A 和 B,那么两者的服务都可用时的流程如下:
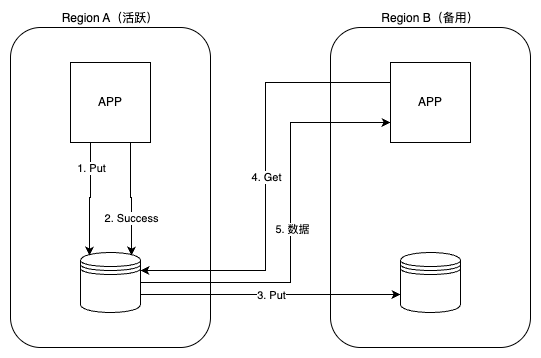
客户端(App A)向 Region A 的 DynamoDB 表写入数据,写操作一旦在 Region A 达到持久化,立即返回成功给 App A,保证写入延迟最低(最终一致性或强一致性均可选)。DynamoDB 利用 Global Tables 机制,通过内部的 DynamoDB Streams 将写操作异步推送到 Region B 的副本表,在平时可让 Region B 的应用(App B)直接从 Region A 读取最新数据。副本表会在通常 1 秒内同步到最新写入项,Get 操作返回数据给 App B。
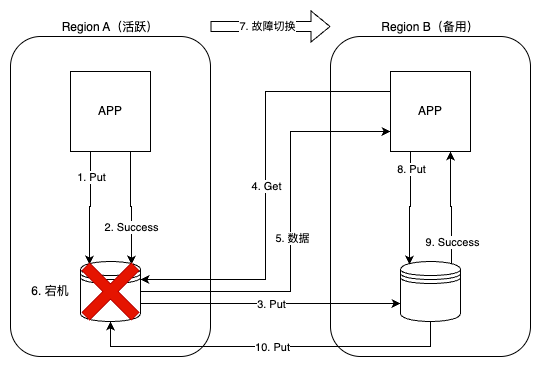
如果完成上图的第五步之后,Region A 的数据存储宕机,那么 DynamoDB 基于全局表的故障回复和切换如下:
通过 DNS 或客户端配置,将写流量切换到 Region B。切换后,App B 向 Region B 写入新数据,Region B 本地确认写入成功。当 Region A 恢复后,全局表会将 Region B 的变更异步推回 Region A。
复制
Region 内复制
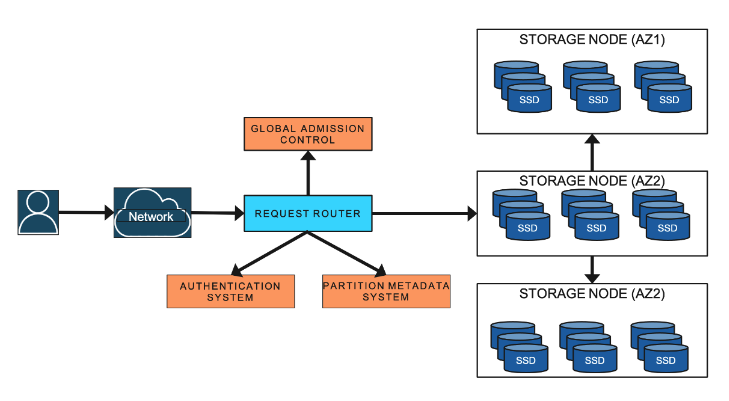
多个可用区(AZ1、AZ2、AZ3)通过高速专有网络互联,数据同步延迟通常在毫秒级。每个 AZ 内都有一份完整数据副本,读写请求可路由至任一 AZ,以提升性能和可用性。
在同一区域内部署的分布式存储通常通过同步复制协议(如 Paxos、Raft)保证写操作在所有 AZ 同步完成后再返回成功,从而确保读写顺序严格一致。
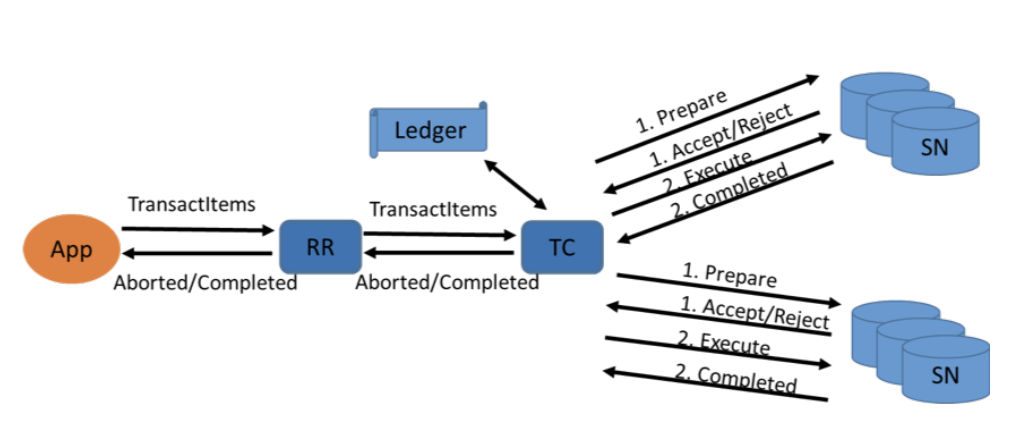
defTransactWriteItem(transact_write_items): # Prepare all items TransactionState = "PREPARING" for operation in transact_write_items: sendPrepareAsyncToSN(operation) waitForAllPreparesToComplete()
# Evaluate whether to commit or cancel the transaction if all_prepares_succeeded(): TransactionState = "COMMITTING" for operation in transact_write_items: sendCommitAsyncToSN(operation) waitForAllCommitsToComplete() TransactionState = "COMPLETED" return"SUCCESS" else: TransactionState = "CANCELLING" for operation in transact_write_items: sendCancellationAsyncToSN(operation) waitForAllCancellationsToComplete() TransactionState = "COMPLETED" return getReasonForCancellation()
为了实现写事务的时间戳排序机制,DynamoDB 在每次写操作(无论是单项写入还是事务写入)后都会将该事务的时间戳记录在对应项上。此外,存储节点还会为每个正在进行的事务持久化事务元数据,包括事务 ID 和时间戳。这些元数据附带在事务涉及的项上,并在分区重分裂等事件中随项迁移,从而确保事务执行不被结构变更干扰,可并行进行。一旦事务结束,这些元数据即被清除。
在协议的准备阶段,事务协调器向每个主存储节点发送一条 prepare 消息,其中包含时间戳、事务 ID 和针对该项的拟执行操作。存储节点仅当以下所有条件都满足时,才接受该事务中的该项写入请求:
if item isnotNone: if ( evaluateConditionsOnItem(item, input.conditions) and evaluateSystemRestrictions(item, input) and item.timestamp < input.timestamp and item.ongoingTransactions isNone ): item.ongoingTransaction = input.transactionId return"SUCCESS" else: return"FAILED" else: # item does not exist item = Item(input.item) if ( evaluateConditionsOnItem(input.item, input.conditions) and evaluateSystemRestrictions(input) and partition.maxDeleteTimestamp < input.timestamp ): item.ongoingTransaction = input.transactionId return"SUCCESS"
Why does DynmoDB not use the two-phase locking protocol?
While two-phase locking is used traditionally to prevent concurrent transactions from reading and writing the same data items, it has drawbacks. Locking restricts concurrency and can lead to deadlocks. Moreover, it requires a recovery mechanism to release locks when an application fails after acquiring locks as part of a transaction but before that transaction commits. To simplify the design and take advantage of low-contention workloads, DynamoDB uses an optimistic concurrency control scheme that avoids locking altogether.
With DynamoDB, what is the role of a transaction coordinator?
The Transaction Coordinator plays a central role in handling transactions that span multiple items or storage nodes. The TC is responsible for:
breaking down the transaction into individual operations and coordinating these operations across the necessary storage nodes.
ensuring that the operations follow two-phase commit and all parts of the transaction are either completed successfully or rolled back.
assigning timestamps to ensure the correct ordering of operations and managing any potential conflicts between concurrent transactions.
Is DynamoDB a relational database management system?
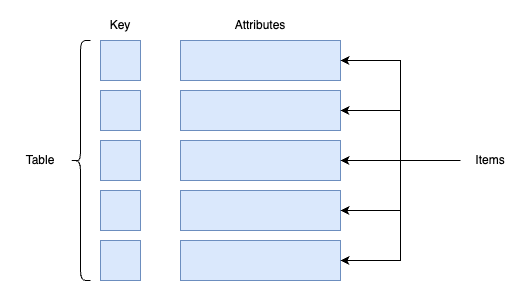
No, DynamoDB is not a relational database management system. It is a NoSQL database, specifically a key-value and document store. Here’s how it differs from an RDBMS:
Data Model: DynamoDB does not use tables with fixed schemas like relational databases. Instead, it stores data as key-value pairs or documents (JSON-like structure). Each item can have different attributes, and there’s no need for predefined schemas.
Relationships: Relational databases focus on managing relationships between data (using joins, foreign keys, etc.), while DynamoDB is optimized for storing large amounts of data without complex relationships between the data items.
Querying: RDBMSs typically use SQL for querying data, which allows for complex joins and aggregations. DynamoDB uses its own API for querying and does not support SQL natively. While it allows querying by primary key and secondary indexes, it doesn’t support joins.
Consistency and Transactions: DynamoDB supports eventual consistency or strong consistency for reads, while traditional relational databases typically ensure strong consistency through ACID transactions. DynamoDB has introduced transactions, but they work differently compared to those in relational databases.
Scalability: DynamoDB is designed for horizontal scalability across distributed systems, allowing it to handle very large amounts of traffic and data by automatically partitioning data. In contrast, RDBMSs are typically vertically scaled and are not as naturally distributed.
How is DynamoDB’s transaction coordinator different than Gamma’s scheduler?
DynamoDB’s transaction coordinator uses Optimistic Concurrency Control (OCC) to manage distributed transactions, ensuring atomicity without 2PC, focusing on scalability and performance in a globally distributed system.
Gamma’s scheduler, on the other hand, uses the traditional Two-Phase Locking (2PL) protocol to guarantee strong consistency in a distributed environment, prioritizing strict coordination across nodes.
Name one difference between FoundationDB and DynamoDB?
FoundationDB: FoundationDB is a multi-model database that offers a core key-value store as its foundation, but it allows you to build other data models (such as documents, graphs, or relational) on top of this key-value layer. It’s highly flexible and provides transactional support for different types of data models via layers.
DynamoDB: DynamoDB is a NoSQL key-value and document store with a fixed data model designed specifically for highly scalable, distributed environments. It does not offer the flexibility of building different models on top of its architecture and is focused on high-performance operations with automatic scaling.
What partitioning strategy does FoundationDB use to distribute key-value pairs across its StorageServers?
FoundationDB uses a range-based partitioning strategy to distribute key-value pairs across its StorageServers.
Here’s how it works:
Key Ranges: FoundationDB partitions the key-value pairs by dividing the key space into contiguous ranges. Each range of keys is assigned to a specific StorageServer.
Dynamic Splitting: The key ranges are dynamically split and adjusted based on data distribution and load. If a particular range grows too large or becomes a hotspot due to frequent access, FoundationDB will automatically split that range into smaller sub-ranges and distribute them across multiple StorageServers to balance the load.
Data Movement: When a key range is split or needs to be rebalanced, the corresponding data is migrated from one StorageServer to another without manual intervention, ensuring even distribution of data and load across the system.
Why do systems such as Nova-LSM separate storage of data from its processing?
Independent Scaling: Storage and processing resources can scale independently to meet varying load demands.
Resource Optimization: Storage nodes focus on data persistence and I/O performance, while processing nodes handle computation, improving overall resource efficiency.
Fault Tolerance: Data remains safe in storage even if processing nodes fail, ensuring high availability.
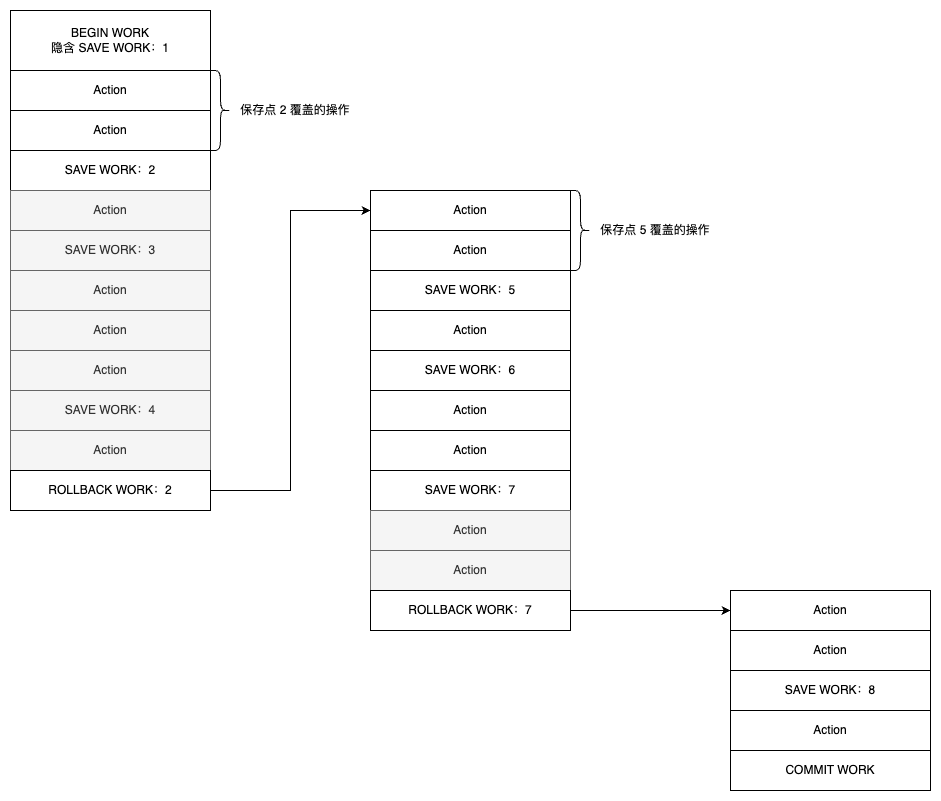
对于扁平的事务来说,其隐式地设置了一个保存点。然而在整个事务中,只有这一个保存点,因此,回滚只能回滚到事务开始时的状态。保存点用 SAVE WORK 函数来建立,通知系统记录当前的处理状态。当出现问题时,保存点能用作内部的重启动点,根据应用逻辑,决定是回到最近一个保存点还是其他更早的保存点。下图显示了在事务中使用保存点。
上图中,灰色背景部分的操作表示由 ROLLBACK WORK 而导致部分回滚,实际上并没有执行的操作。当用 BEGIN WORK 开启一个事务时,隐式地包含了一个保存点;当事务通过 ROLLBACK WORK : 2 发出部分回滚命令时,事务回滚到保存点 2,接着依次执行,并再次执行到 ROLLBACK WORK : 7,直到最后的 COMMIT WORK 操作,这时表示事务结束,除灰色阴影部分的操作外,其余操作都已经执行,并且提交。
mysql>SELECT @@version\G; ERROR 2006 (HY000): MySQL server has gone away No connection. Trying to reconnect... Connection id: 54 Current database: test ***************************1.row*************************** @@version: 5.1.45-log 1rowinset (0.00 sec)
在这个例子中,设置了 completion_type=2 后,执行 COMMIT WORK 不仅提交了事务,而且释放(关闭)了当前连接。重新执行任何查询时,客户端都会发现与服务器的连接已断开,并尝试重新连接。
SAVEPOINT 记录了一个保存点,可以通过 ROLLBACK TO SAVEPOINT 来回滚到某个保存点,但是如果回滚到一个不存在的保存点,会抛出异常:
1 2 3 4 5
mysql>BEGIN; Query OK, 0rows affected (0.00 sec)
mysql>ROLLBACKTOSAVEPOINT t1; ERROR 1305 (42000): SAVEPOINT t1 does not exist
ALTER DATABASE … UPGRADE DATA DIRECTORY NAME ALTER EVENT ALTERPROCEDURE ALTER TABLE ALTERVIEW CREATE DATABASE CREATE EVENT CREATE INDEX CREATEPROCEDURE CREATE TABLE CREATETRIGGER CREATEVIEW DROP DATABASE DROP EVENT DROP INDEX DROPPROCEDURE DROPTABLE DROPTRIGGER DROPVIEW RENAME TABLE TRUNCATETABLE
用来隐式地修改 MySQL 架构的操作:
1 2 3 4 5 6
CREATEUSER DROPUSER GRANT RENAME USER REVOKE SET PASSWORD
管理语句:
1 2 3 4 5 6
ANALYZE TABLE CACHE INDEX CHECKTABLE LOAD INDEX INTO CACHE OPTIMIZE TABLE REPAIR TABLE
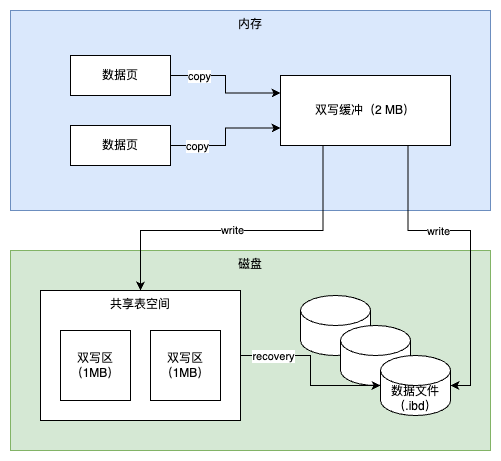
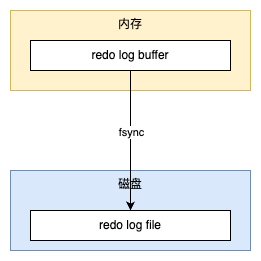
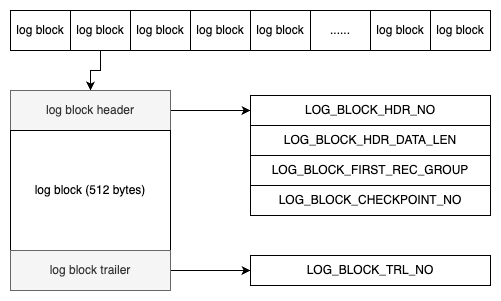
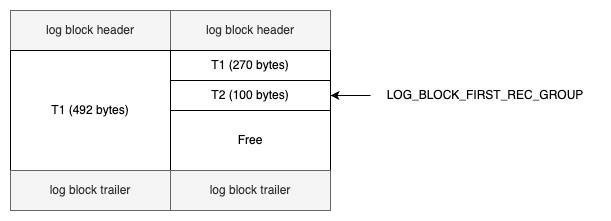
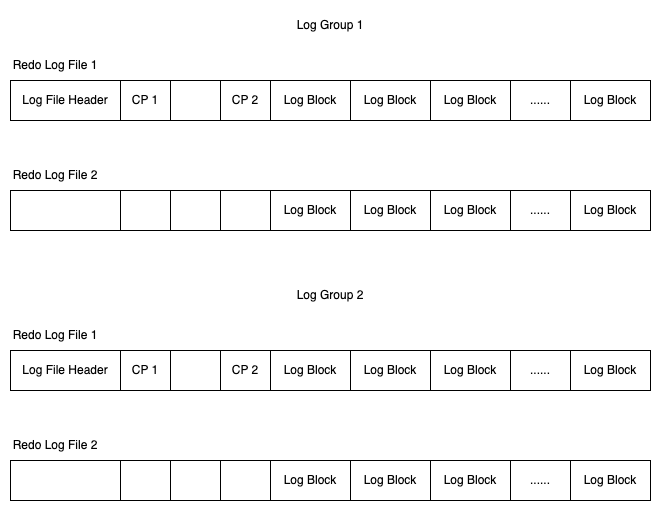
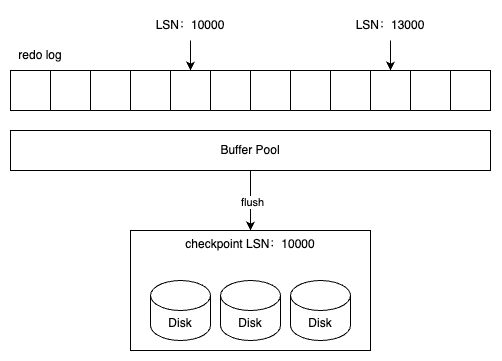
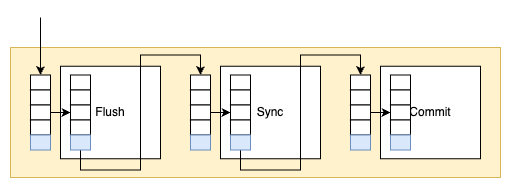
虽然在上面的例子中,Log sequence number 和 Log flushed up to 的值是相同的,但是在实际生产环境中,该值有可能是不同的。因为在一个事务中从日志缓冲刷新到重做日志文件并不只是在事务提交时发生,每秒都会有从日志缓冲刷新到重做日志文件的动作。下面是在生产环境下重做日志的信息的示例。
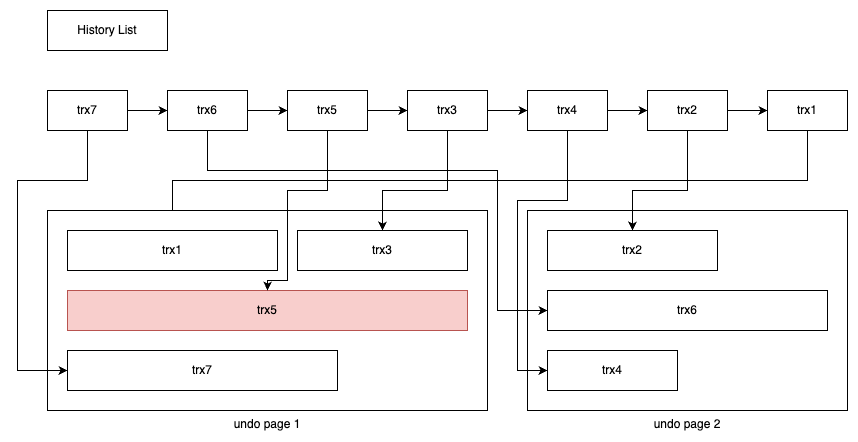
当 InnoDB 存储引擎的压力非常大时,并不能高效地进行 purge 操作。那么 history list 的长度会变得越来越长。全局动态参数 innodb_max_purge_lag 用来控制 history list 的长度,若长度大于该参数时,其会延缓 DML 的操作。该参数默认值为 0,表示不对 history list 做任何限制。当大于 0 时,就会延缓 DML 的操作,其延缓的算法为:
这个问题最早在 2010 年的 MySQL 数据库大会中提出,Facebook MySQL 技术组、Percona 公司都提出过解决方案。最后由 MariaDB 数据库的开发人员 Kristian Nielsen 完成了最终的“完美”解决方案。在这种情况下,不但 MySQL 数据库上层的二进制日志写入是 group commit 的,InnoDB 存储引擎层也是 group commit 的。此外还移除了原先的锁 prepare_commit_mutex,从而大大提高了数据库的整体性。MySQL 5.6 采用了类似的实现方式,并将其称为 Binary Log Group Commit(BLGC)。
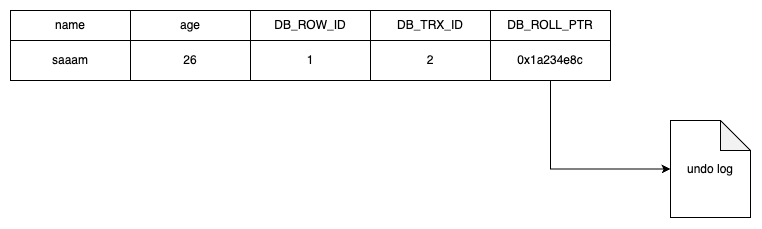
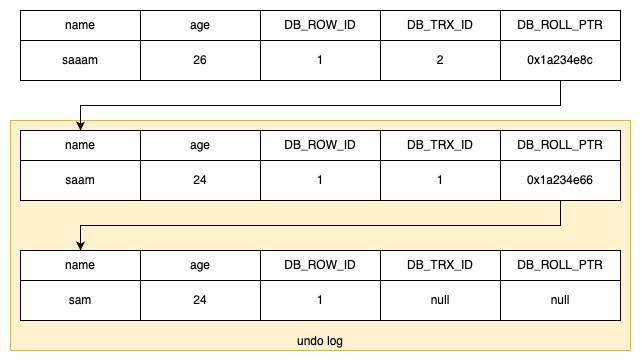
假设读事务开启了一个 ReadView,这个 ReadView 里面记录了当前活跃事务的 ID 列表(444、555、665),以及最小事务 ID(444)和最大事务 ID(666)。当然还有自己的事务 ID 520,也就是 creator_trx_id。它要读的这行数据的写事务 ID 是 x,也就是 DB_TRX_ID。
事务冲突与回滚:如果多个事务在同一行上发生冲突(例如,事务 A 在修改一行数据时,事务 B 也试图修改同一行数据),事务 B 会等待事务 A 完成。当事务 A 提交后,事务 B 才能继续进行。如果事务 A 回滚,那么事务 B 仍然可以继续修改该行,因为回滚后数据恢复到了事务 A 之前的状态。
如果其他三个特性都能够得到保证,那一致性也就能得到保证了。例如:
如果一个事务回滚,原子性确保数据库回到之前的状态;
隔离性确保事务之间的干扰最小化,避免不一致;
持久性确保事务提交后修改不会丢失。
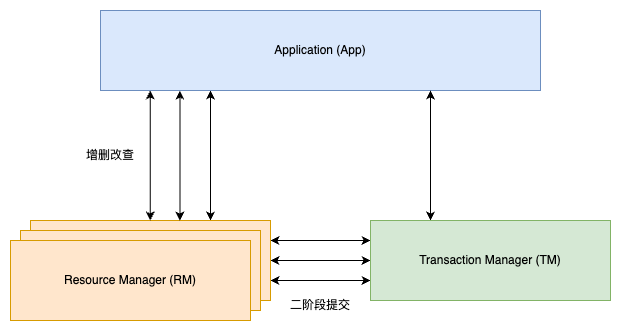
分布式事务
在 MySQL 数据库中,InnoDB 存储引擎提供了对 XA 事务的支持,并通过 XA 事务来实现分布式事务。分布式事务指的是允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求其中的所有参与事务要么都提交,要么都回滚,这对事务原有的 ACID 要求提出了更高的要求。此外,在使用分布式事务时,InnoDB 存储引擎的事务隔离级别必须设置为 SERIALIZABLE。
XA 事务允许在不同数据库之间进行分布式事务。比如,一台服务器上运行 MySQL 数据库,另一台服务器上运行 Oracle 数据库,甚至还可能有一台运行 SQL Server 数据库,只要所有参与全局事务的节点都支持 XA 事务即可。分布式事务在银行系统的转账场景中比较常见,例如用户 David 需要从上海的账户转账 10 000 元到北京用户 Mariah 的银行卡中:
1 2 3 4 5
# Bank@Shanghai: UPDATE account SET money = money -10000WHEREuser='David';
# Bank@Beijing: UPDATE account SET money = money +10000WHEREuser='Mariah';
在这种情况下,一定需要使用分布式事务来保证数据的安全性。如果操作不能全部提交或全部回滚,那么任何一个节点出现问题都会导致严重后果:要么 David 的账户被扣款但 Mariah 没收到钱,要么 David 的账户没有扣款但 Mariah 收到钱。
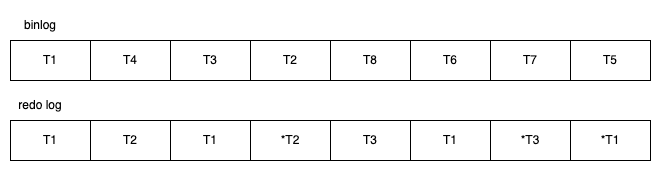
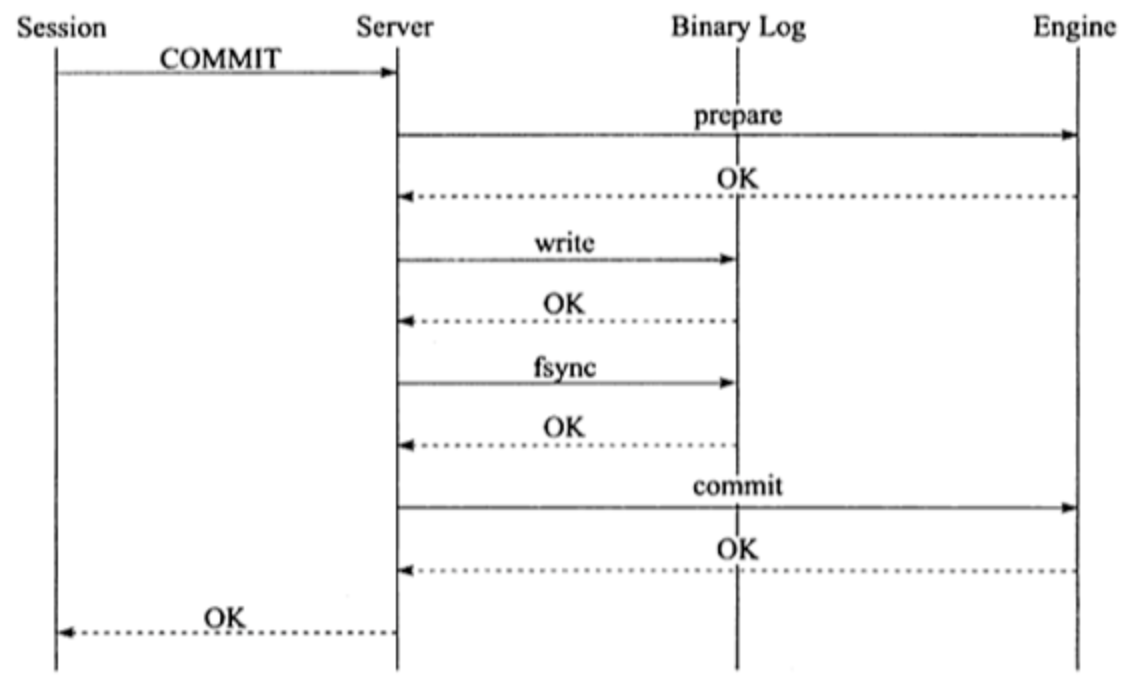
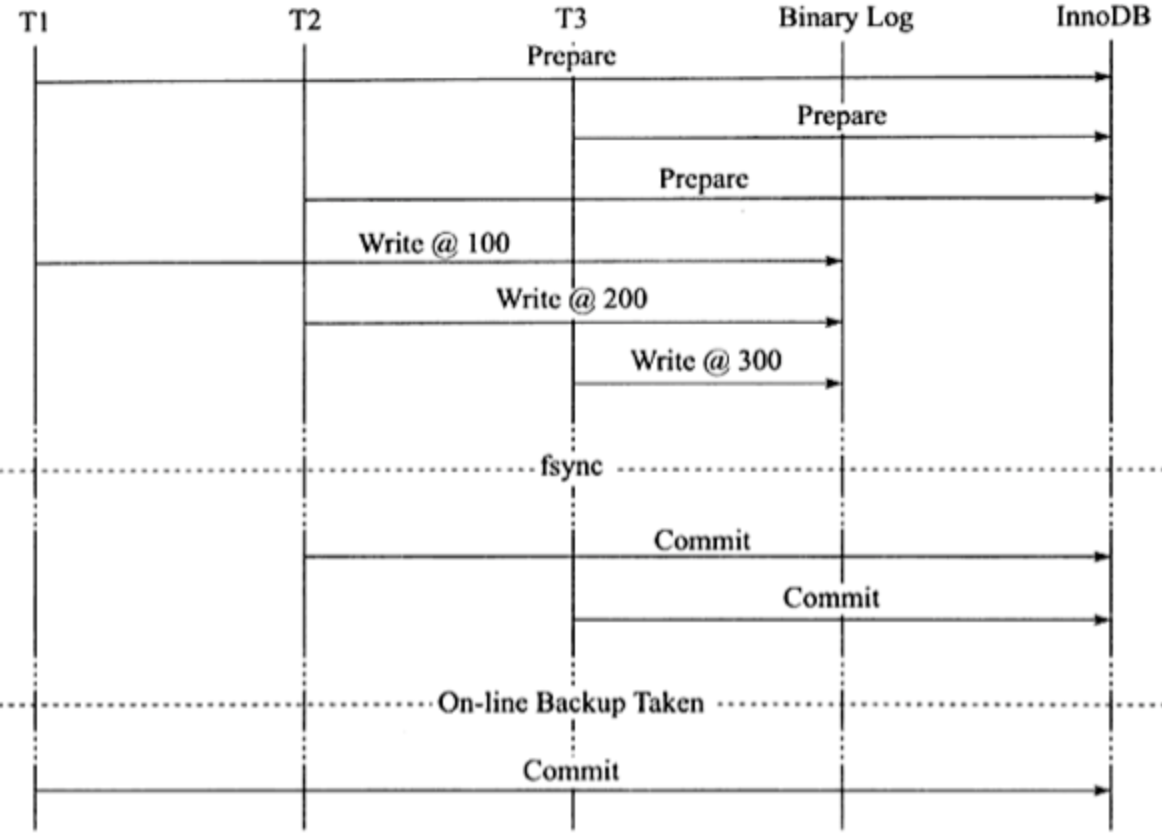
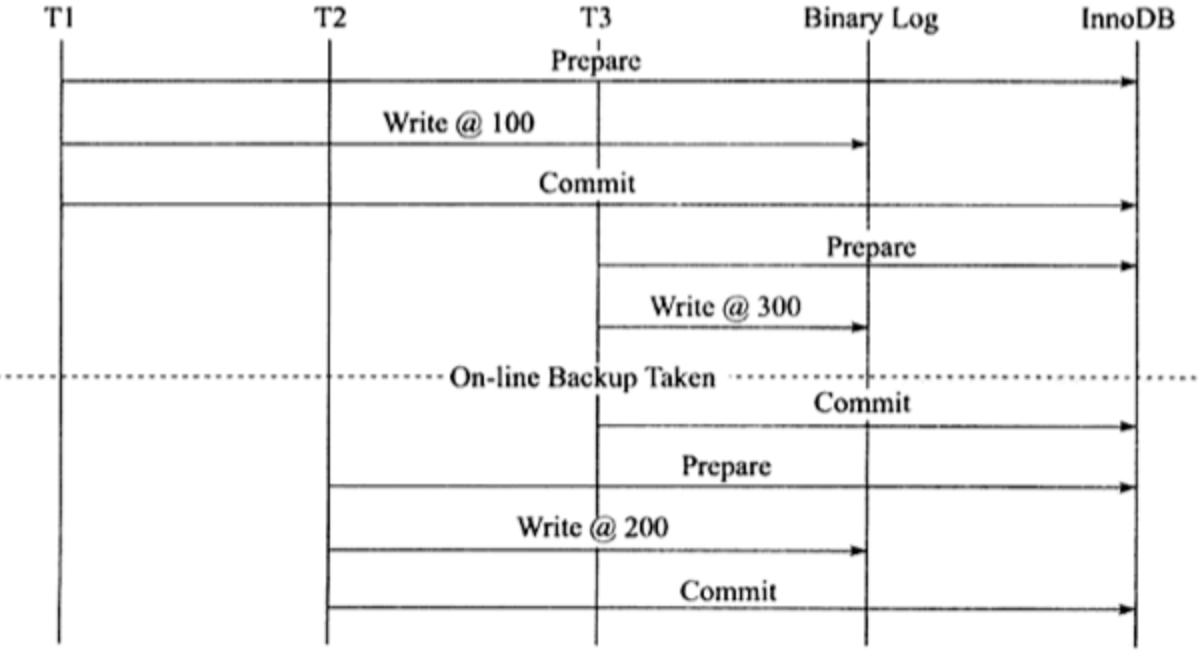
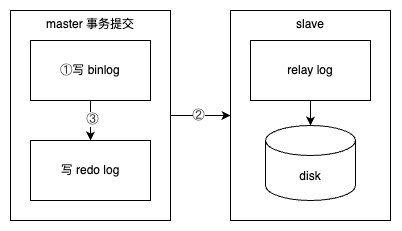
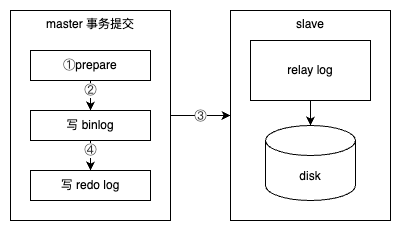
在上图中,如果执行完 ①、② 后在步骤 ③ 之前 MySQL 数据库发生了宕机,则会发生主从不一致的情况。为了解决这个问题,MySQL 数据库在 binlog 与 InnoDB 存储引擎之间采用 XA 事务。当事务提交时,InnoDB 存储引擎会先做一个 PREPARE 操作,将事务的 xid 写入,接着进行二进制日志的写入,如下图所示。如果在 InnoDB 存储引擎提交前,MySQL 数据库宕机了,那么 MySQL 数据库在重启后会先检查准备的 UXID 事务是否已经提交,若没有,则在存储引擎层再进行一次提交操作。
不好的事务习惯
在循环中提交
开发人员可能会在循环中进行事务的提交,如下(可想象成 Java 中的某个方法):
1 2 3 4 5 6 7 8 9 10
CREATEPROCEDURE load1(count INT UNSIGNED) BEGIN DECLARE s INT UNSIGNED DEFAULT1; DECLARE c CHAR(80) DEFAULT REPEAT('a',80); WHILE s <= count DO INSERT INTO t1 SELECTNULL, c; COMMIT; SET s = s +1; END WHILE; END;
CREATEPROCEDURE load3(count INT UNSIGNED) BEGIN DECLARE s INT UNSIGNED DEFAULT1; DECLARE c CHAR(80) DEFAULT REPEAT('a',80); START TRANSACTION; WHILE s <= count DO INSERT INTO t1 SELECTNULL, c; SET s = s +1; END WHILE; COMMIT; END;