Intro
FoundationDB的研究意义在于,它成功地将NoSQL的灵活性与ACID事务的强大功能结合在一起,提供了一种模块化的架构,使得各个子系统可以独立配置和扩展。这种设计不仅提高了系统的可扩展性和可用性,还增强了故障容忍能力。此外,FoundationDB采用了严格的模拟测试框架,确保了系统的稳定性和高效性,使得开发者能够快速引入和发布新特性。FoundationDB的快速恢复机制显著提高了系统的可用性,简化了软件升级和配置变更的过程,通常在几秒钟内完成。
The main design principles are:
- Divide-and-Conquer (or separation of concerns). FDB decouples the transaction management system (write path) from the distributed storage (read path) and scales them independently. Within the transaction management system, processes are assigned various roles representing different aspects of transaction management. Furthermore, cluster-wide orchestrating tasks, such as overload control and load balancing are also divided and serviced by additional heterogeneous roles.
- Make failure a common case. For distributed systems, failure is a norm rather than an exception. To cope with failures in the transaction management system of FDB, we handle all failures through the recovery path: the transaction system proactively shuts down when it detects a failure. Thus, all failure handling is reduced to a single recovery operation, which becomes a common and well-tested code path. To improve availability, FDB strives to minimize Mean-Time-To-Recovery (MTTR). In our production clusters, the total time is usually less than five seconds.
- Simulation testing. FDB relies on a randomized, deterministic simulation framework for testing the correctness of its distributed database. Simulation tests not only expose deep bugs, but also boost developer productivity and the code quality of FDB.
Architecture
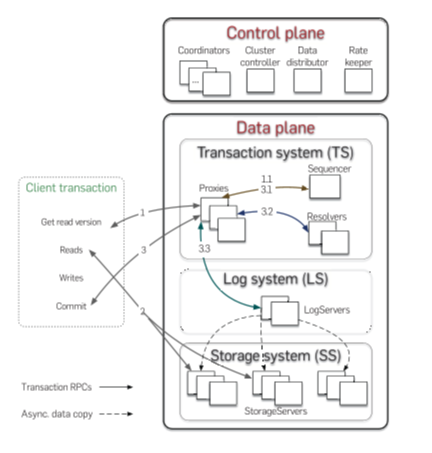
The control plane is responsible for persisting critical system metadata, that is, the configuration of transaction systems, on Coordinators.
These Coordinators form a Paxos group and elect a ClusterController.
The ClusterController monitors all servers in the cluster and recruits three processes, Sequencer, DataDistributor, and Ratekeeper, which are re-recruited if they fail or crash.
The DataDistributor is responsible for monitoring failures and balancing data among StorageServers.
Ratekeeper provides overload protection for the cluster.
The data plane is responsible for transaction processing and data storage. FDB chooses an unbundled architecture:
A distributed transaction management system (TS) consists of a Sequencer, Proxies, and Resolvers, all of which are stateless processes.
The Sequencer assigns a read and a commit version to each transaction.
Proxies offer MVCC read versions to clients and orchestrate transaction commits.
Resolvers check for conflicts among transactions.
A log system (LS) stores Write-Ahead-Log (WAL) for TS, and a separate distributed storage system (SS) is used for storing data and servicing reads. The LS contains a set of LogServers and the SS has a number of StorageServers. LogServers act as replicated, sharded, distributed persistent queues, each queue storing WAL data for a StorageServer.
Clients read from sharded StorageServers, so reads scale linearly with the number of StorageServers.
Writes are scaled by adding more Proxies, Resolvers, and LogServers.
The control plane’s singleton processes (e.g., ClusterController and Sequencer) and Coordinators are not performance bottlenecks; they only perform limited metadata operations. 因为元数据操作少且简单,且与两者无关的数据读写是并行扩展的(如上面两行加粗字体所述)。
Bootstrapping
FDB has no dependency on external coordination services. All user data and most system metadata (keys that start with 0xFF prefix) are stored in StorageServers. The metadata about StorageServers is persisted in LogServers, and the LogServers configuration data is stored in all Coordinators.
- The Coordinators are a disk Paxos group; servers attempt to become the ClusterController if one does not exist.
- A newly elected ClusterController reads the old LS configuration from the Coordinators and spawns a new TS and LS.
- Proxies recover system metadata from the old LS, including information about all StorageServers.
- The Sequencer waits until the new TS finishes recovery, then writes the new LS configuration to all Coordinators. The new transaction system is then ready to accept client transactions.
Reconfiguration
The Sequencer process monitors the health of Proxies, Resolvers, and LogServers. Whenever there is a failure in the TS or LS, or the database configuration changes, the Sequencer terminates. The ClusterController detects the Sequencer failure, then recruits and bootstraps a new TS and LS. In this way, transaction processing is divided into epochs, where each epoch represents a generation of the transaction management system with its own Sequencer.
End-to-end transaction processing
Transaction Start and Read Operations:
A client starts a transaction by contacting a Proxy to obtain a read version (timestamp).
The Proxy requests a read version from the Sequencer that is greater than all previously issued commit versions and sends it to the client.
The client then reads from StorageServers at this specific read version.
Buffered Write Operations:
Client writes are buffered locally and not sent to the cluster immediately.
Read-your-write semantics are preserved by combining the database lookups with the client’s uncommitted writes.
Transaction Commit:
When the client commits, it sends the transaction data (read and write sets) to a Proxy, waiting for either a commit or abort response.
The Proxy commits a transaction in three steps:
Obtain Commit Version: The Proxy requests a commit version from the Sequencer that is larger than all current read or commit versions.
Conflict Check: The Proxy sends transaction data to the partitioned Resolvers, which check for read-write conflicts. If no conflicts are found, the transaction proceeds; otherwise, it is aborted.
Persist to Log Servers: The transaction is sent to LogServers for persistence, and after all LogServers acknowledge, the transaction is considered committed. The Proxy then reports the committed version to the Sequencer and sends the response back to the client.
Applying Writes:
- StorageServers continuously pull mutation logs from LogServers and apply the committed changes to disk.
Read-Only Transactions and Snapshot Reads:
Read-only transactions are serializable (at the read version) and high-performance (thanks to MVCC), allowing the client to commit locally without contacting the database, which is particularly important since most transactions are read-only.
Snapshot reads relax the isolation property of a transaction, reducing conflicts by allowing concurrent writes without conflicting with snapshot reads.
FoundationDB (FDB) using Serializable Snapshot Isolation (SSI) by combining Optimistic Concurrency Control (OCC) with Multi-Version Concurrency Control (MVCC).
Transaction Versions
- Each transaction receives a read version and a commit version from the Sequencer.
- The read version ensures that the transaction observes the results of all previously committed transactions, and the commit version is greater than all current read or commit versions, establishing a serial order for transactions.
Log Sequence Number (LSN)
- The commit version serves as the LSN, defining a serial history of transactions.
- To ensure no gaps between LSNs, the Sequencer also returns the previous LSN with each commit. Both the LSN and previous LSN are sent to Resolvers and LogServers to enforce serial processing of transactions.
Conflict Detection
- FDB uses a lock-free conflict detection algorithm similar to write-snapshot isolation, but the commit version is chosen before conflict detection, enabling efficient batch processing of version assignments and conflict detection.
- The key space is divided among multiple Resolvers, allowing conflict detection to be parallelized. A transaction can commit only if all Resolvers confirm no conflicts.
Handling Aborted Transactions
- If a transaction is aborted, some Resolvers may have already updated their history, leading to possible “false positive” conflicts for other transactions. However, this is rare because most transactions’ key ranges fall within one Resolver, and the effects of false positives are limited to a short MVCC window (5 seconds).
Efficiency of OCC
- The OCC design avoids the complexity of acquiring and releasing locks, simplifying interactions between the Transaction System (TS) and Storage Servers (SS).
- While OCC may result in some wasted work due to aborted transactions, FDB’s conflict rate in production is low (less than 1%), and clients can simply restart aborted transactions.
Logging protocol
Commit Logging:
- Once a Proxy decides to commit a transaction, it sends the transaction’s changes (mutations) to the LogServers responsible for the modified key ranges. Other LogServers receive an empty message.
- The log message includes the current and previous Log Sequence Number (LSN) from the Sequencer and the largest known committed version (KCV) of the Proxy.
- The LogServers reply to the Proxy once the log data is durably stored. The Proxy updates its KCV if all replica LogServers acknowledge and the LSN is larger than the current KCV.
Shipping Redo Logs:
- Shipping the redo log from LogServers to StorageServers happens in the background and is not part of the commit path, improving performance.
Applying Redo Logs:
- StorageServers apply non-durable redo logs from LogServers to an in-memory index. In most cases, this happens before any client reads are processed, ensuring low-latency multi-version reads.
- If the requested data is not yet available on a StorageServer, the client either waits or retries at another replica. If both reads time out, the client can restart the transaction.
I/O Efficiency:
- Since log data is already durable on LogServers, StorageServers can buffer updates in memory and write batches to disk periodically, improving input/output (I/O) efficiency.
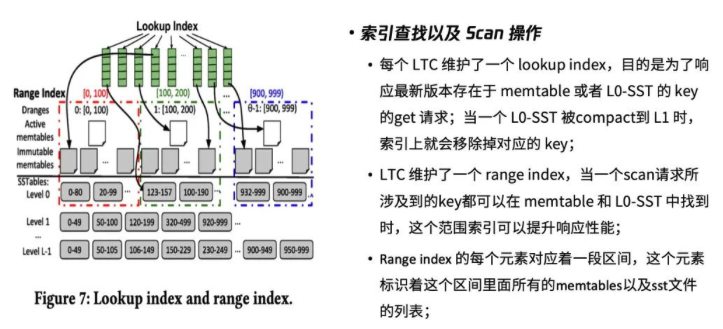
What if a StorageServer is lagging behind on applying the redo logs and a client requests a version of a key pair it does not have?
- Wait for a threshold for when known-committed-version is greater than or equal to the read version
- If timeout, the client asks another StorageServer that stores the key
- Return error “request for a future version” (FDB error code 1009)
What if there is no further transaction logs to redo?
- Without new transactions issued from the client, proxies still generate empty transactions to advance the known-committed-version
- Known-committed-version and LSN of each transaction are sent to all LogServers (limit scalability on writes)
Transaction system recovery
Simplified Recovery
- Unlike traditional databases that require undo log processing, FoundationDB avoids this step by making the redo log processing the same as the normal log forward path. StorageServers pull logs from LogServers and apply them in the background.
Failure Detection and New Transaction System (TS)
- Upon detecting a failure, a new TS is recruited. The new TS can start accepting transactions even before all old logs are fully processed. Recovery focuses on finding the end of the redo log, allowing StorageServers to asynchronously replay the logs from that point.
Epoch-based Recovery
- The recovery process is handled per epoch. The ClusterController locks the old TS configuration, stops old LogServers from accepting new transactions, recruits a new set of transaction components (Sequencer, Proxies, Resolvers, and LogServers), and writes the new TS configuration to the Coordinators.
- Stateless components like Proxies and Resolvers don’t require special recovery, but LogServers, which store committed transaction logs, must ensure all data is durable and retrievable by StorageServers.
Recovery Version (RV)
- The recovery focuses on determining the Recovery Version (RV), which is essentially the end of the redo log. The Sequencer collects data from the old LogServers, specifically the Durable Version (DV) (maximum LSN persisted) and KCV (maximum committed version) from each.
- Once enough LogServers have responded, the Previous Epoch Version (PEV) is established (the maximum of all KCVs). The start version of the new epoch is
PEV + 1, and the minimum DV becomes the RV.
Log Copying and Healing
- Logs between
PEV + 1and RV are copied from old LogServers to the new ones to restore replication in case of LogServer failures. This copying process is lightweight since it only covers a few seconds of logs.
Rollback and Transaction Processing
- The first transaction after recovery is a special recovery transaction that informs StorageServers of the RV, so they can discard in-memory multi-versioned data beyond the RV. StorageServers then pull data larger than the PEV from the new LogServers.
- The rollback process simply discards in-memory multi-versioned data, as persistent data is only written to disk once it leaves the MVCC window.
Replication
Metadata Replication:
- System metadata related to the control plane is stored on Coordinators using the Active Disk Paxos protocol. As long as a majority (quorum) of Coordinators are operational, the metadata can be recovered in case of failure.
Log Replication:
- When a Proxy writes logs to LogServers, each log record is replicated synchronously across k = f + 1 LogServers (where f is the number of allowed failures). The Proxy only sends a commit response to the client after all k LogServers have successfully persisted the log. If a LogServer fails, a transaction system recovery is triggered.
Storage Replication:
- Each key range (shard) is asynchronously replicated across k = f + 1 StorageServers. These StorageServers form a team. A StorageServer typically hosts multiple shards, distributing its data across several teams. If a StorageServer fails, the DataDistributor moves the data from teams with the failed server to other healthy teams.
To prevent data loss in case of simultaneous failures, FoundationDB ensures that no more than one process in a replica group is placed within the same fault domain (e.g., a host, rack, or availability zone). As long as one process in each team is operational, no data is lost, provided at least one fault domain remains available.
Simulation testing
Deterministic Simulation:
FoundationDB uses deterministic discrete-event simulation to test its distributed system. This simulation runs real database code along with randomized synthetic workloads and fault injection to uncover bugs.
Determinism ensures that bugs are reproducible and can be investigated thoroughly.
Fault Injection:
The simulation tests system resilience by injecting various faults, such as machine, rack, or data center failures, network issues, disk corruption, and delays.
Randomization of these faults increases the diversity of tested states, allowing for a wide range of potential issues to be examined.
“Buggification” is a technique used to deliberately introduce rare or unusual behaviors (e.g., unnecessary delays, errors) in the system to stress-test its handling of non-standard conditions.
Swarm Testing:
Swarm testing increases simulation diversity by using random cluster sizes, configurations, workloads, and fault injection parameters.
This ensures that a broad range of scenarios is covered in testing, allowing for the discovery of rare bugs.
Test Oracles:
Test oracles are built into the system to verify key properties like transaction atomicity, isolation, and recoverability. Assertions check these properties to detect failures during simulation.
They help confirm that the system’s expected behaviors are maintained, even under stressful conditions.
Bug Detection Efficiency:
The simulation runs faster than real-time, allowing FoundationDB to quickly discover and trace bugs. The parallel nature of testing accelerates the process of finding bugs, particularly before major releases.
This approach uncovers bugs that may not appear during real-time testing, especially for issues that require long-running operations.
Limitations:
Simulation cannot reliably detect performance issues (like imperfect load balancing).
It cannot test third-party libraries or external dependencies, focusing mainly on FoundationDB’s internal code and behaviors.
Lessons learned
Architecture Design
Divide-and-Conquer Principle: Separating the transaction system from the storage layer allows for independent scaling and deployment of resources, enhancing both flexibility and performance.
LogServers as Witness Replicas: In multi-region deployments, LogServers reduce the need for full StorageServer replicas while maintaining high availability.
Role Specialization: The design enables the creation of specialized roles, like separating DataDistributor and Ratekeeper from the Sequencer, and separating Proxies into Get-Read-Version and Commit Proxies, which improves performance and makes the system extensible.
Decoupling Enhances Extensibility: This design pattern allows features like replacing SQLite with RocksDB and adding new roles or functions without overhauling the entire system.
Simulation Testing
High Productivity: FDB’s deterministic simulation testing enables bugs to be found and reproduced quickly. This approach has improved developer productivity and system reliability by reducing debugging time and improving test coverage.
Reliability: FDB has operated without any data corruption over several years of deployment (e.g., CloudKit), thanks to rigorous simulation testing. Simulation has allowed ambitious rewrites and improvements to be made safely.
Eliminating Dependencies: Simulation testing helped find bugs in external dependencies, leading to FDB replacing Apache Zookeeper with its own Paxos implementation. This change resulted in no further production bugs.
Fast Recovery
Simplifies Upgrades: FDB allows fast recovery by restarting all processes simultaneously, typically within seconds, simplifying software upgrades and configuration changes. This method has been extensively tested and used in Apple’s production clusters.
Bug Healing: Fast recovery can automatically resolve certain latent bugs, similar to software rejuvenation, by resetting system states.
5-Second MVCC Window
Memory Efficiency: FDB uses a 5-second MVCC (Multi-Version Concurrency Control) window to limit memory usage in transaction systems and storage servers. This time window is long enough for most OLTP workloads, exposing inefficiencies if the transaction exceeds 5 seconds.
TaskBucket Abstraction: Long-running processes, like backups, are broken into smaller transactions that fit within the 5-second window. FDB implements this through an abstraction called TaskBucket, which simplifies splitting large transactions into manageable jobs.
Questions
With FDB, what operations does a transaction commit perform when the transaction only reads the value of data items?
- Read Version Retrieval: The client requests a read version from a Proxy via the Sequencer, which guarantees the read version is greater than or equal to any committed version.
- Read Operation: The client reads the requested data at this specific read version from the StorageServers. The reads are served by the StorageServers, which are guaranteed to provide data consistent with the requested version.
- No Writes or Conflicts: Since the transaction is read-only, there is no write set or conflicts to check. The transaction simply ends, and no data is written or modified, meaning it does not interact with LogServers or commit any changes.
- Commit: Even though no actual commit occurs (because there’s no data change), the transaction is marked as successfully completed after the reads are done.
With FDB, is it possible for multiple resolvers to participate in the decision whether to commit or abort a write transaction?
Yes, multiple Resolvers can participate in the decision to commit or abort a write transaction in FDB. Here’s how it works:
- Conflict Detection: When a transaction writes data, the write set (the keys it wants to write) is sent to a set of Resolvers. Each Resolver is responsible for a specific portion of the key space. Multiple Resolvers can be involved in checking the transaction’s read and write sets to detect conflicts (read-write conflicts or write-write conflicts).
- Parallel Conflict Checking: Since the key space is partitioned, different Resolvers check different key ranges in parallel. A transaction can only commit if all Resolvers agree that there are no conflicts.
With FDB, what if a StorageServer is lagging behind on applying the redo logs and a client requests a version of a key pair it does not have?
- Client Waits: The client can choose to wait for the StorageServer to catch up by applying the redo logs. Once the StorageServer finishes replaying the logs and reaches the required version, it can serve the requested data.
- Retry at Another Replica: If the StorageServer does not have the requested version yet, the client can try to read from another replica of the key. FDB typically stores multiple replicas of data across different StorageServers, so the client can retry the request from a replica that is up to date.
- Transaction Restart: If neither replica has the requested version or the delay is too long, the client may restart the transaction. Since FoundationDB uses MVCC (Multi-Version Concurrency Control), restarting the transaction allows it to obtain a fresh version of the key from an up-to-date StorageServer.
Consider a database for students enrolling in courses and professors teaching those courses. Provide a SDM model of this database?
Students: base concrete object class.
member property: student_id, name, age, email, department_id.
identifier: student_id.
Professors: base concrete object class.
member property: professor_id, name, age, email, department_id.
identifier: professor_id.
Courses: base concrete object class
member property: course_id, name, location, start_time, end_time, department_id.
derived member property: professor as Professors.professor_id.
identifier: course_id.
Enrollment: base duration event class.
member property: enrollment_id, date_of_enrollment.
member participant: student in Students, course in Courses.
identifier: enrollment_id.
Departments: abstract Students and Professors on common value of department_id.
derived member property: department_id as distinct value of (Students.department_id union Professors.department_id).
What is the difference between a monolithic database management system and a disaggregated database management system?
| Feature | Monolithic DBMS | Disaggregated DBMS |
|---|---|---|
| Architecture | All components tightly integrated into a single system | Components like storage, computation, and query processing are separated |
| Scalability | Scales through vertical scaling (adding resources to the single server) | Scales through horizontal scaling (independent scaling of storage and compute) |
| Performance Bottlenecks | May face bottlenecks as the system grows | Components are independently optimized, reducing bottlenecks |
| Resource Management | Storage and compute resources are tightly coupled, hard to manage separately | Storage and compute resources can be managed independently, offering flexibility |
| Complexity | Easier to deploy and manage initially, but complexity increases with scale | More complex to manage and coordinate different components |
| Cost | Pay for all resources, even if they are not fully utilized | Can optimize resource usage and costs by scaling components independently |
| Consistency | Strong data consistency due to tight integration | Requires additional mechanisms to ensure consistency across components |
With Gamma and its data flow execution paradigm, how does the system know when the execution of a parallel query involving multiple operators is complete?
Data Dependency Graph: The query execution is modeled as a directed acyclic graph (DAG), where each node represents an operator (e.g., selection, join). Data flows between operators, and the system tracks the completion of each operator based on this graph.
Completion Signals: Each parallel operator sends a “done” signal once it finishes processing its data partition. The system monitors these signals to determine when all operators have finished.
Coordinator: A central coordinator tracks the progress of parallel tasks. When all tasks report completion, the system declares the query execution as complete.
Reference: https://sigmodrecord.org/publications/sigmodRecord/2203/pdfs/08_fdb-zhou.pdf