Intro
LSM-Tree(Log-Structured Merge Tree)的核心思想是将大量的随机写入转换为更高效的顺序写入。简单来说,它通过以下方式来实现:
- 写入内存:当有新的数据写入时,LSM-Tree首先将这些数据存储在内存中的缓冲区(称为MemTable)。这是一个有序的结构,数据按键排序。
- 批量写入磁盘:当内存中的数据积累到一定程度时,整个MemTable会被一次性地写入磁盘,这个过程是顺序写入,非常高效。写入磁盘后,这个数据成为一个不可修改的文件,称为SSTable(Sorted String Table)。
- 合并和压缩:随着时间的推移,磁盘上会产生多个SSTable。为了优化读取性能,系统会周期性地将这些SSTable进行合并和压缩,使得数据保持有序并减少冗余。
这样,LSM-Tree通过将频繁的随机写操作缓存在内存中,最后批量顺序写入磁盘,大大提高了写入性能。这种方式适合写入密集型的工作负载,同时还能保证数据查询的效率。
LSM-Tree的基础结构,特别是数据如何从内存(memtable)移动到磁盘,并经过多级的归并排序(compaction)过程来进行存储。
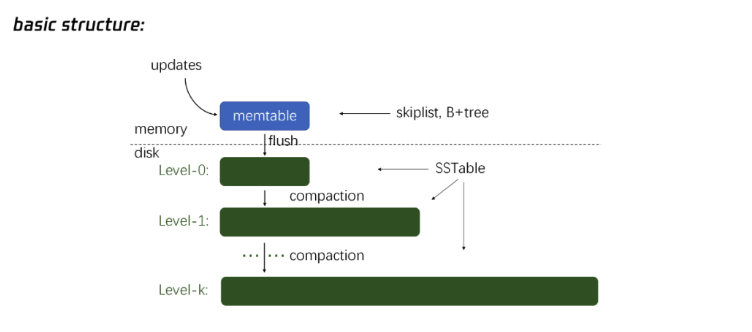
MemTable(内存表)
数据的写入首先进入到内存中的memtable,通常是一个有序的数据结构(比如跳表或B+树),这使得数据在内存中是有序的,便于快速写入和查询。
当memtable满了或者系统需要将数据持久化时,memtable中的数据会被flush(刷新)到磁盘,形成第一层的SSTable。
Level-0(磁盘上的第一层)
数据从内存写入磁盘后,存储在Level-0层的SSTable中。此时,SSTable的数据顺序与memtable一致,但可能存在多个SSTable,且它们之间的键值范围可能重叠。
Level-0的SSTable是逐渐积累的,并不会自动排序或整理,直到执行compaction(归并操作)。
Compaction(归并操作)
当Level-0层的数据达到一定量时,系统会执行归并操作,将Level-0层的多个SSTable合并,并将合并后的有序数据移到Level-1层。
Level-1开始,所有的SSTable都是有序且互不重叠的。也就是说,每个SSTable都有自己独立的键值范围,不会与其他SSTable的键值范围重叠,这使得查询时能够快速定位到目标SSTable。
逐级沉降
数据会随着系统运行,从Level-0层逐步沉降到更深的层级(如Level-1、Level-2等)。在每一层,数据都通过归并操作变得更加有序且结构紧凑。
每次合并后,数据被重新整理,分配到新的不重叠的SSTable中,从而保持物理上的键值有序性。
LSM-Tree查询
基于LSM-Tree的查询可分为点查与范围查询两大类,对应的执行方式如下:
- 点查(point lookup):从上往下进行查询,先查memtable,再到L0层、L1层。因为上层的数据永远比下层版本新,所以在第一次发生匹配后就会停止查询。
- 范围查询(range lookup):每一层都会找到一个匹配数据项的范围,再将该范围进行多路归并,归并过程中同一key只会保留最新版本。
LSM-Tree性能的衡量主要考虑三个因素:空间放大、读放大和写放大。
一是空间放大(space amplification)。LSM-Tree的所有写操作都是顺序追加写,对数据的更新并不会立即反映到数据既有的值里,而是通过分配新的空间来存储新的值,即out-place update。因此冗余的数据或数据的多版本,仍会在LSM-Tree系统里存在一定时间。这种实际的占用空间大于数据本身的现象我们称之为空间放大。因为空间有限,为了减少空间放大,LSM-Tree会从L1往L2、L3、L4不断做compaction,以此来清理过期的数据以及不同数据的旧版本,从而将空间释放出来。
二是读放大(read amplification)。假设数据本身的大小为1k,由于存储结构的设计,它所读到的值会触发多次IO操作,一次IO意味着一条读请求,这时它所读取到的则是在后端所需要做大的磁盘读的实际量,已经远大于目标数据本身的大小,从而影响到了读性能。这种现象我们称之为读放大。为了减轻读放大,LSM-Tree采用布隆过滤器来避免读取不包括查询键值的SST文件。
三是写放大(write amplification)。在每层进行compaction时,我们会对多个SST文件进行反复读取再进行归并排序,在删掉数据的旧版本后,再写入新的SST文件。从效果上看,每条key在存储系统里可能会被多次写入,相当于一条key在每层都会写入一次,由此带来的IO性能损失即写放大。
LSM-Tree最初的理念是用空间放大和读放大来换取写放大的降低,从而实现较好的写性能,但也需要做好三者的平衡。以下是两种假设的极端情况。
第一种极端情况是:如果完全不做compaction,LSM-Tree基本等同于log文件,当memtable不断刷下来时,由于不做compaction,只做L0层的文件,这时如果要读一条key,读性能会非常差。因为如果在memtable里找不到该条key,就要去扫描所有的SST文件,但与此同时写放大现象也将不存在。
第二种极端情况是:如果compaction操作做到极致,实现所有数据全局有序,此时读性能最优。因为只需要读一个文件且该文件处于有序状态,在读取时可以很快找到对应的key。但要达到这种效果,需要做非常多的compaction操作,要不断地把需要删的SST文件读取合并再来写入,这会导致非常严重的写放大。
Nova-LSM架构设计
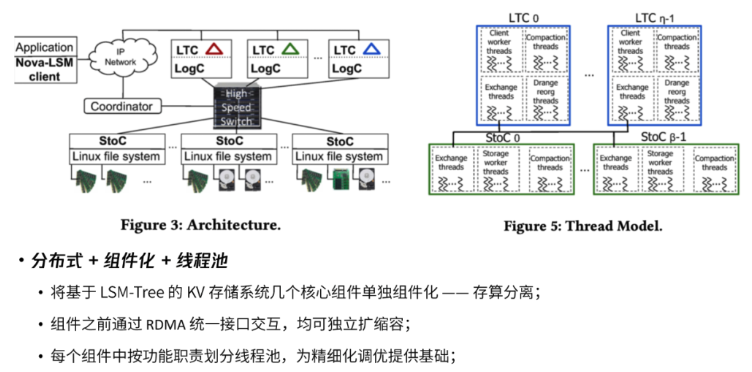
第一部分是写日志的组件,将WAL写成功后再往LSM-Tree的memtable中查询新的数据。
第二部分是本身处理LSM-Tree写入的线程,其缩写为LTC(LSM-Tree Component),代表着将该线程单独组件化。
第三部分则是底层的存储,负责把接收到的上层LTC组件下发下来,并提供标准的文件接口。
Nova-LSM所解决的核心问题
第一个核心问题是:基于LSM-Tree结构的存储系统,例如LevelDB、RocksDB等,都会不可避免地遇到缓写或者停写的问题。比如内存里的memtable,在配置时最多可以写8个,因为写入多,需要全部flush到磁盘上。与此同时,当前L0层的SST文件非常多,L0层即将开始做compaction。但compaction会涉及到磁盘IO,在还没做完时,就会阻塞内存中的memtable对L0层SST进行flush的过程。当flush无法进行时,就会发生缓写,随着阈值的推进,在实在写不进时甚至会停写,这种现象体现在客户端就是请求掉零。
为了解决LSM-Tree结构存储系统中的缓写、停写问题,该文章提出了两个解决办法:
- 第一种方法是设计了存算分离的架构体系,具体如上图所示。该架构的重要作用之一,是把处理写入和处理磁盘IO的两大主力模块拆分,计算存储分离,哪个部分慢就为哪个部分增加节点以此来提高该部分的能力,这是比较亮眼的突破。
- 第二种方法是引入了动态分区,即Drange机制。该机制的目的是为了让业务的写入压力,在LTC即计算层的memtable上进行区间划分,每个range都有自己的memtable,通过区间划分,从而实现多个range之间进行并行compaction。以L0层为例,我们可以把L0层变成没有互相重叠的状态,这时我们就可以对L0层进行并行的compaction,可以加快L0层的文件的消化,从而减轻对memtable flush到磁盘上的过程的影响。
第二个核心问题是:在这种方式下需要划分很多不同的Drange,每个range都会增加一定的memtable数量,memtable数量的增加会影响scan和get的性能。假设有一个主请求,在原来所有数据都写在一个memtable里的情况下,在读取时,索引只需要面向这个memtable,再根据跳表进行get,如果get到则可以马上返回。现在划分成不同的Drange,memtable数量增加,因此需要查找的memtable以及L0层的SST也会变多。解决办法是:实现了一个索引,可以查询到一个key在memtable或L0 SST中的最新值(若存在)。
Nova-LSM 中的重要设计
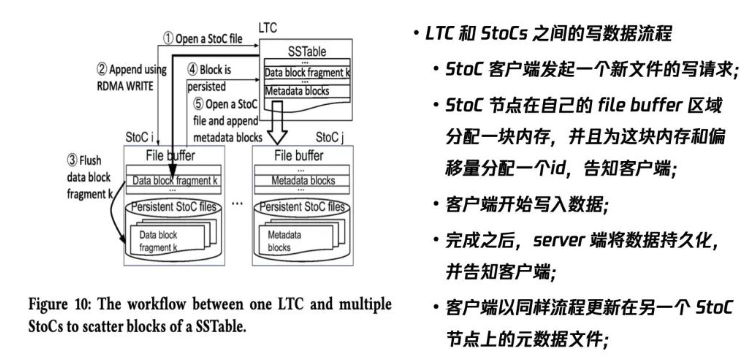
LTC和StoCs之间的写数据流程
第一个比较重要的设计是LTC和StoCs之间的写数据流程。该流程展示的是:当在客户端发起写请求时,计算节点和存储节点是以怎样的方式将数据写进去的过程。
首先是计算节点的客户端发起一个新的写请求操作。存储节点在接收到该请求后,基于RDMA交互,它会在buffer区域分配一个内存区域,并且为这块内存和偏移量(当前哪块内存可以写)分配一个id,告知客户端。客户端接到响应后就会开始写数据,完成后会通知存储节点。存储节点接收到信号后,将数据持久化并且再告知客户端。
上述流程是写一个数据文件即SSTable。写完后,我们要以同样的流程将元数据文件更新。因为底层是分布式架构,需要知道哪些文件写在哪里以及每个SST的范围、版本号。
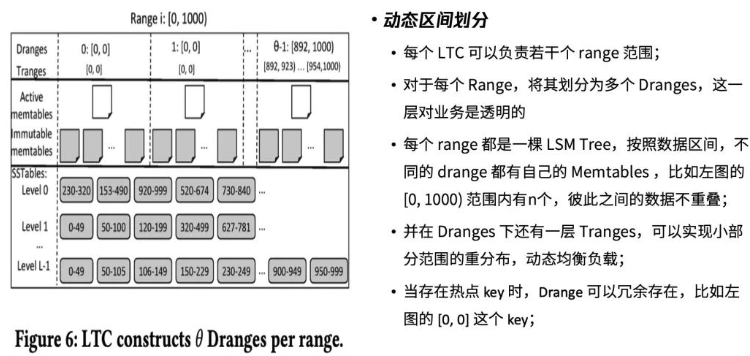
动态区间划分
第二个比较重要的设计是动态区间划分。假设业务的请求范围为0-1万,当前有10个计算节点,将这10个计算节点的区间划分为10等份,比如第一个key的空间范围为0-1000。在负责0-1000的计算节点里,它会再进行划分,这一层划分业务无感知。这就叫动态区间划分,简称Drange。其作用主要有以下几点:
首先,每个range都是一棵LSM-Tree,按照数据区间,不同的Drange都有自己的memtables。比如0-1000区间又可以划分为10个Drange,10个Drange之间的memtable相互独立。这样做的好处是这些Drange之间的key互不重叠,例如0-100、100-200、200-300。
其次,在Dranges下还有一层Tranges。如果发现Drange里的部分range比如890-895存在热点现象,而旁边的range并非热点,则可以用Tranges进行细粒度的复杂重均衡,实现动态均衡负载。
最后,在此基础上,因为Drange的key范围互不相交,当memtable变成immutable,不可再写后,它们需要独立地flush到磁盘上。这时,在L0层的SSTable来自不同的Drange,它们之间的key完全不相交,我们就可以进行并行的compaction。
文章还将没有Drange划分和有Drange划分两种情况进行了对比:
- 在没有Drange划分的情况下,L0的compaction无法很好并行。在这种情况下,如果遇到最坏的情况,L0层的某一个SST有可能覆盖了整个key空间,假设key范围为0-600,L0层的SST文件的范围是0-1000,当发生compaction时,它必须要跟其他4个SST做归并,这时不但要把L0层的其他SST全部读取比较一遍,还要把L1层所有的SST都读一遍再做归并排序。这时写放大会较为严重,意味着L0层到L1层的compaction会变慢,flush也会变慢,甚至flush不了时,前端就会出现缓写、停写现象。
- 有Drange划分后,相当于compaction可以分开区间,如下方的示意图所示。在0-100区间,L0到L1可以独立去compaction,100-200区间也可以独立去compaction,可以较好地实现并行compaction。而在原生的RocksDB里,只有从L1开始compaction,才能进行并行compaction操作。
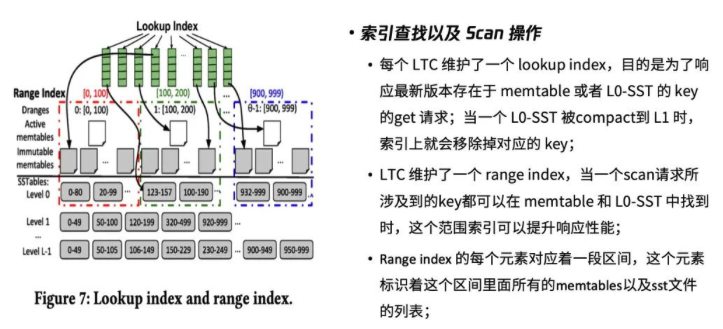
索引查找以及Scan操作
因为划分了很多不同的动态区间,memtable的数量也会增加,意味着查询操作的耗时也会增加。所以要如何在原来的基础上维护好读性能?这篇文章提出了以下解决思路:
每个LTC维护了一个lookup index。如果这些数据存在于memtable和L0层的SST上,通过lookup index我们就可以快速查找到想要的数据。当某一个L0层SST被compaction到L1层时,索引上就会移除掉对应的key。
LTC同时还维护了一个范围索引即range index。因为知道每个Drange的范围,所以当一个scan请求所涉及到的key都可以在memtable和L0层SST中找到时,该范围索引就能快速响应scan操作。
SSTable的分布
最后一个比较重要的设计涉及到存储层。当某个SST文件要写到存储节点时,分布式系统首先要保证负载均衡,要保证数据避免单点故障不可恢复的场景。
该文章提出根据一定策略,将数据文件即SST打散写入到多个存储节点里。考虑到存储成本,每个SSTable采用纠删码(Erasure Coding)的方式进行编码然后分布式存放。默认情况下对每个 SSTable 采用 “3+1”的 EC 配置,将一个SSTable切分为3个数据块,根据一定算法,在这3个数据块里去计算出一个校验块,变成了“3+1”的形式。这种方式比传统的多副本可以节省更多空间。假设一个SSTable是3M,这种“3+1”的方式最终所占空间为4M,并且能容忍一个节点的丢失,与占用6M空间的双副本方案拥有同样的故障容忍等级。而元数据文件因为体积比较小,所以直接采用多副本存储的方式,比如1个元数据文件可以写3个副本。
Challenges and Solutions
Write Stalls, the solutions are:
Vertical scaling: use large memory.
Horizontal scaling: use the bandwidth of many StoCs.
Scans are slowed down, the solutions are:
Construct Dranges at runtime based on workload. Drange faciliates parallel compaction.
Construct range index dynamically.
Gets are slowed down, the solution is: Use lookup index.
Temporary Bottlenecks, the solution is:
Scatter blocks of a SSTable across multiple StoCs.
Power-of-d: power-of-d is applied in Nova-LSM to help with load balancing during SSTable placement. When writing data to storage components (StoCs), Nova-LSM doesn’t randomly select just one StoC. Instead, it chooses d StoCs at random and writes to the one with the shortest queue. This method helps avoid bottlenecks and improves throughput, ensuring that data is distributed evenly across storage nodes without overwhelming any individual node.
Logging, the solution is: Replicating Log records in the memory of StoCs to provide high availability.
Skewed Access Pattern, the solution is: Dranges enable LTC to write 65% less data to StoCs with skewed data access.
Questions
Why do modern database systems disaggregate compute from storage?
Modern database systems disaggregate compute from storage to improve scalability, resource utilization, and fault isolation. By separating compute (processing) and storage, the system can independently scale each based on demand. Compute nodes handle processing, while storage nodes handle data access, optimizing resources and ensuring that failures in one component don’t impact the other. This separation also benefits cloud environments, where elastic scaling of resources is crucial.
How does Nova-LSM provide superior performance than monolithic data stores?
Nova-LSM improves performance by using a component-based architecture that disaggregates processing (LTC) and storage (StoC). It allows components to scale independently and uses RDMA for fast communication. Nova-LSM also introduces dynamic range partitioning (Dranges), allowing parallel compaction and reducing write stalls, which significantly enhances throughput. This architecture minimizes bottlenecks seen in monolithic stores like LevelDB and RocksDB, especially under skewed workloads.
Why does the standard cost-based optimizer produce sub-optimal query plans? How does Kepler improve both the query planning time and query execution time?
The standard cost-based optimizer can produce sub-optimal plans because it relies on simplified and static cost models that don’t always capture real execution costs, especially in dynamic environments. It also may lack up-to-date statistics, leading to inaccurate decisions. Kepler, on the other hand, uses machine learning to learn from past executions and adapts to current data distributions, improving query plan selection. By pruning the search space efficiently and using real-time data, it reduces both planning time and execution time while optimizing performance.
References: